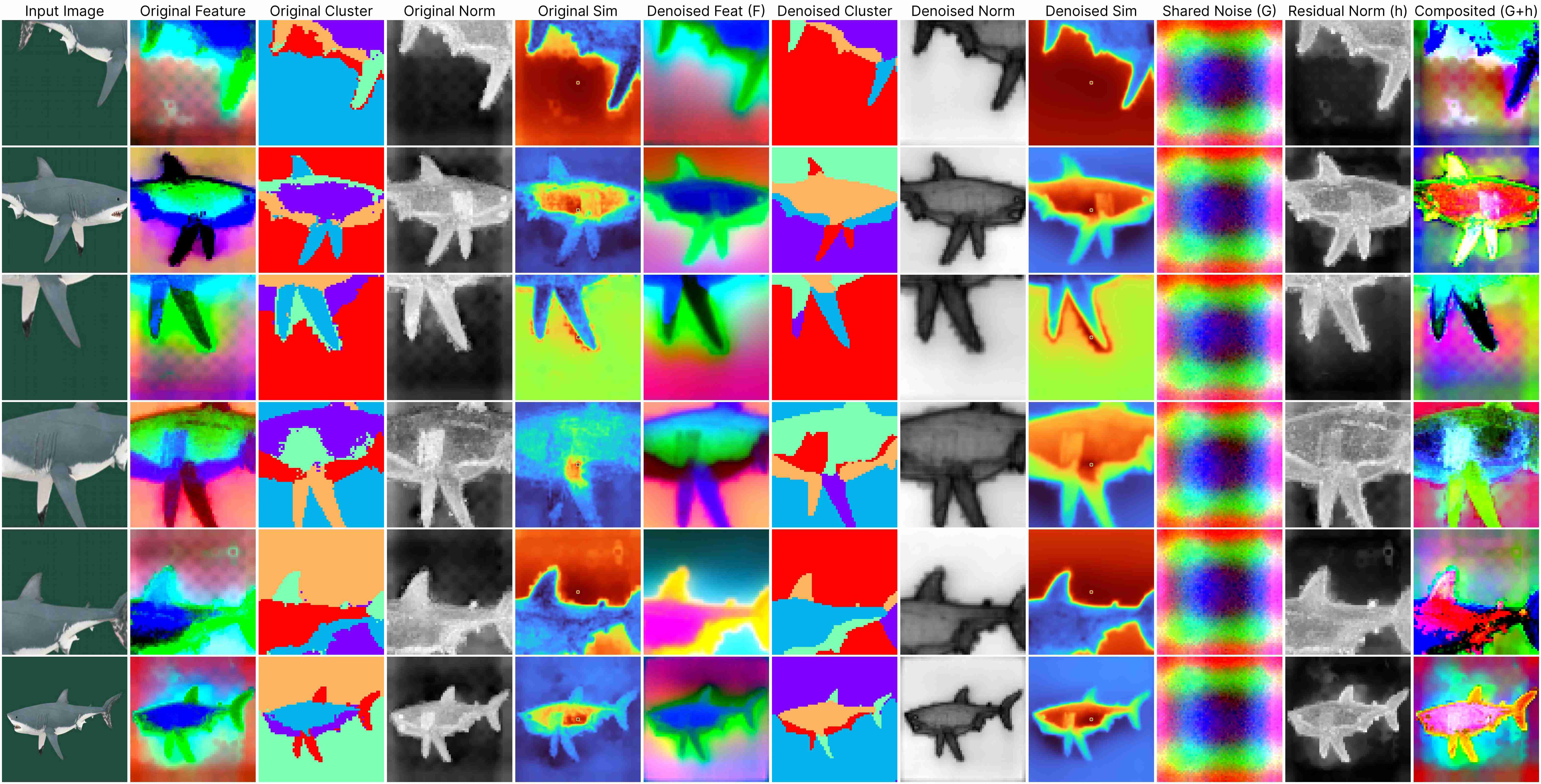


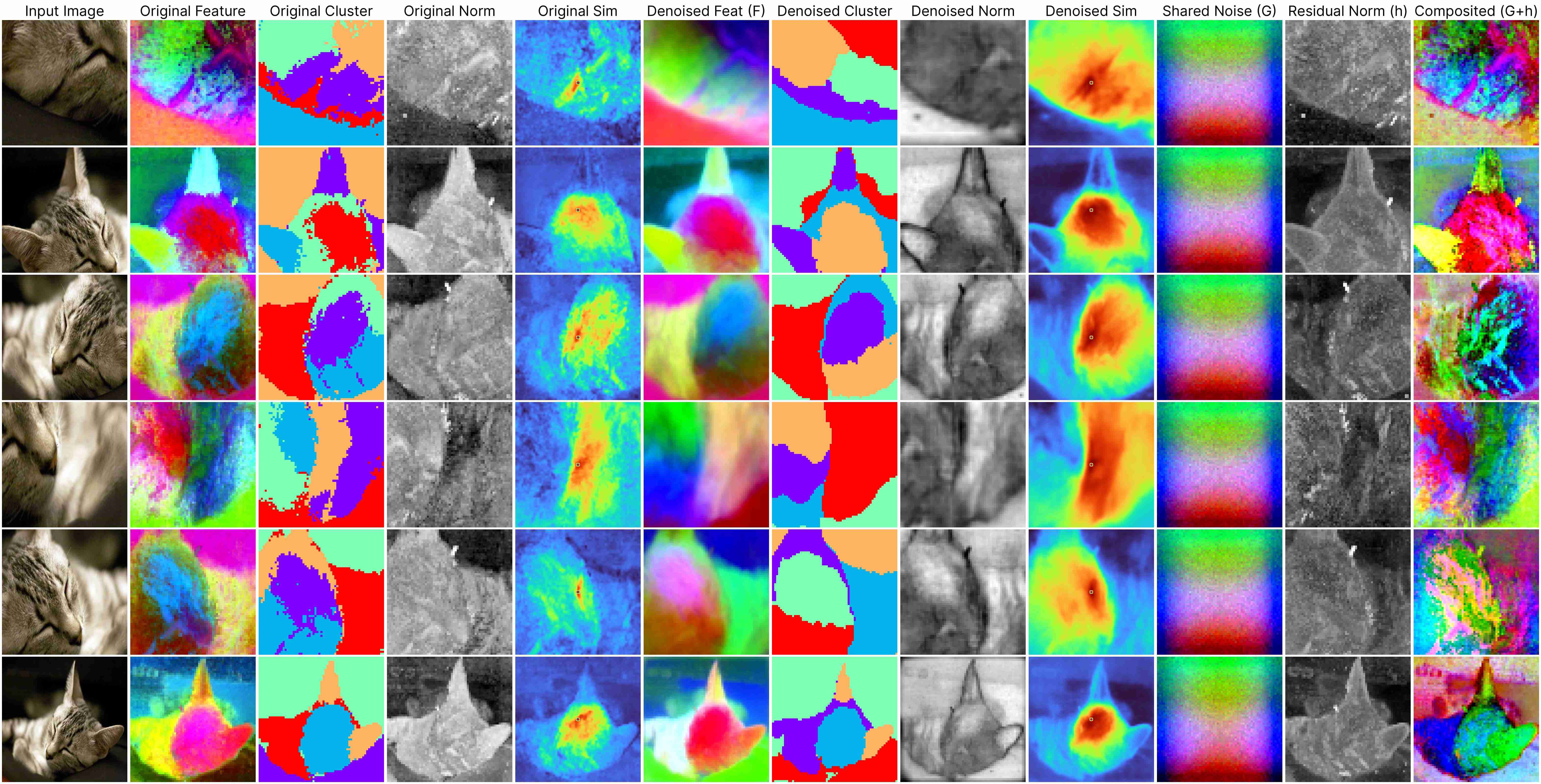
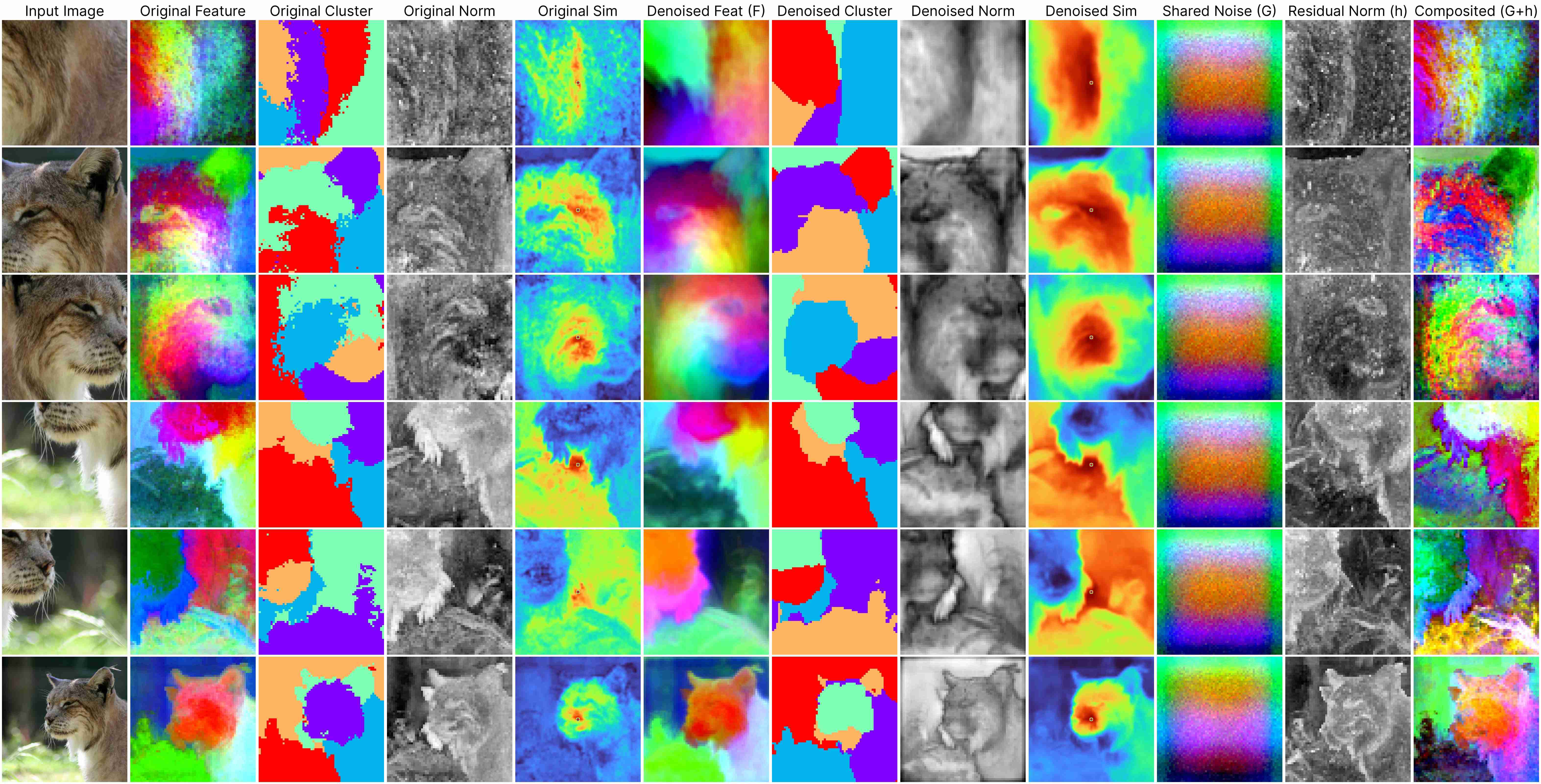


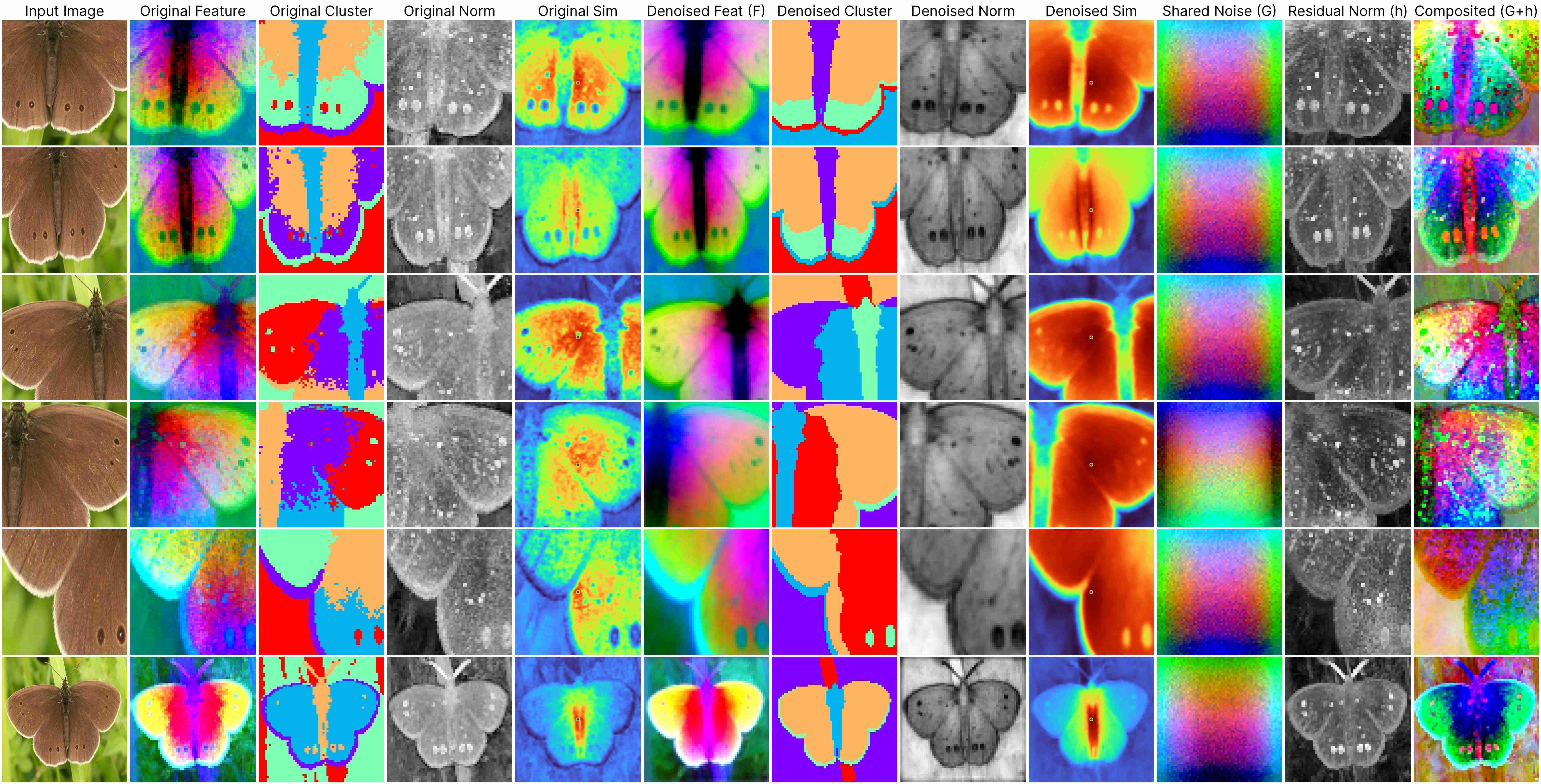
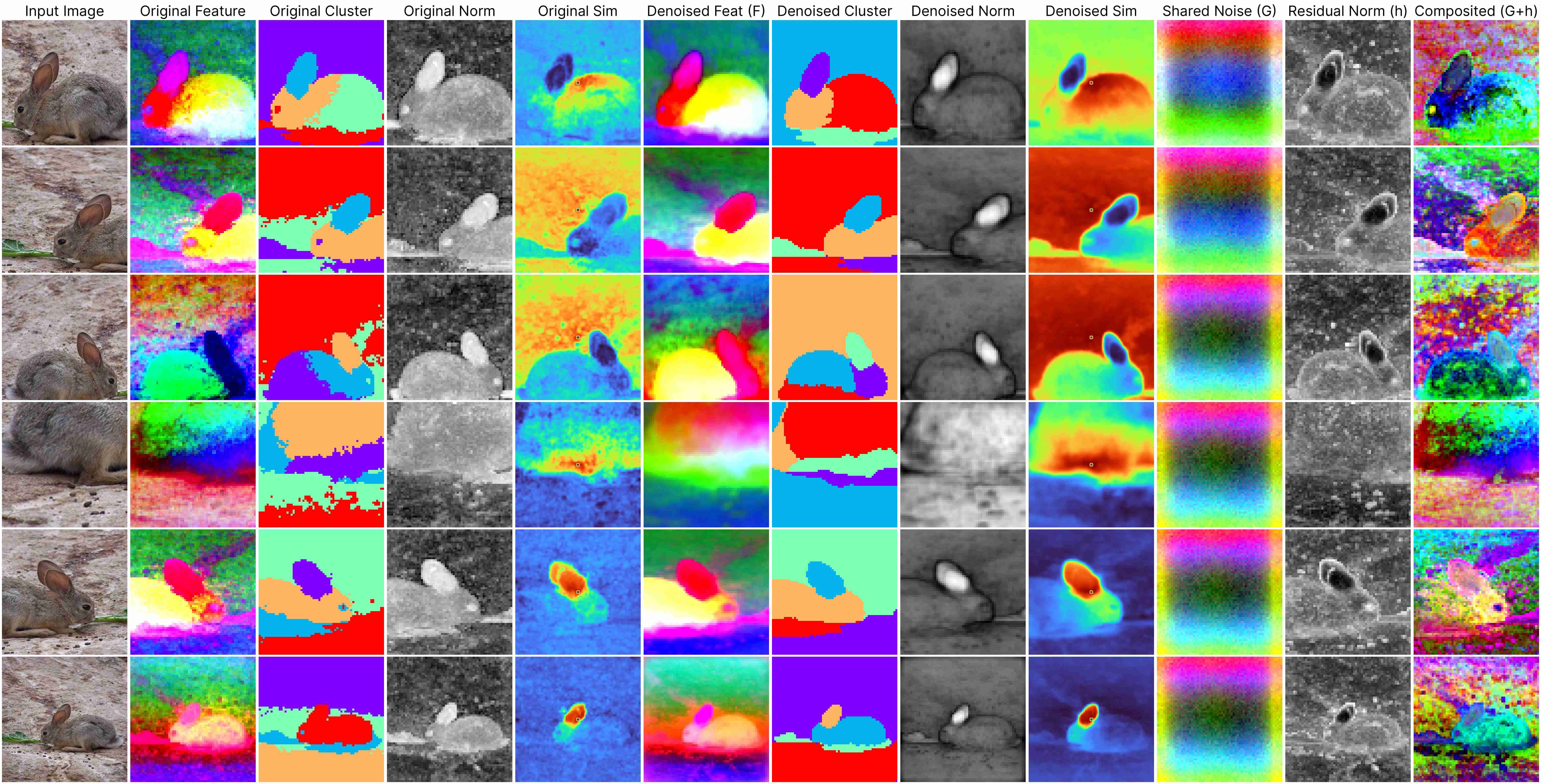

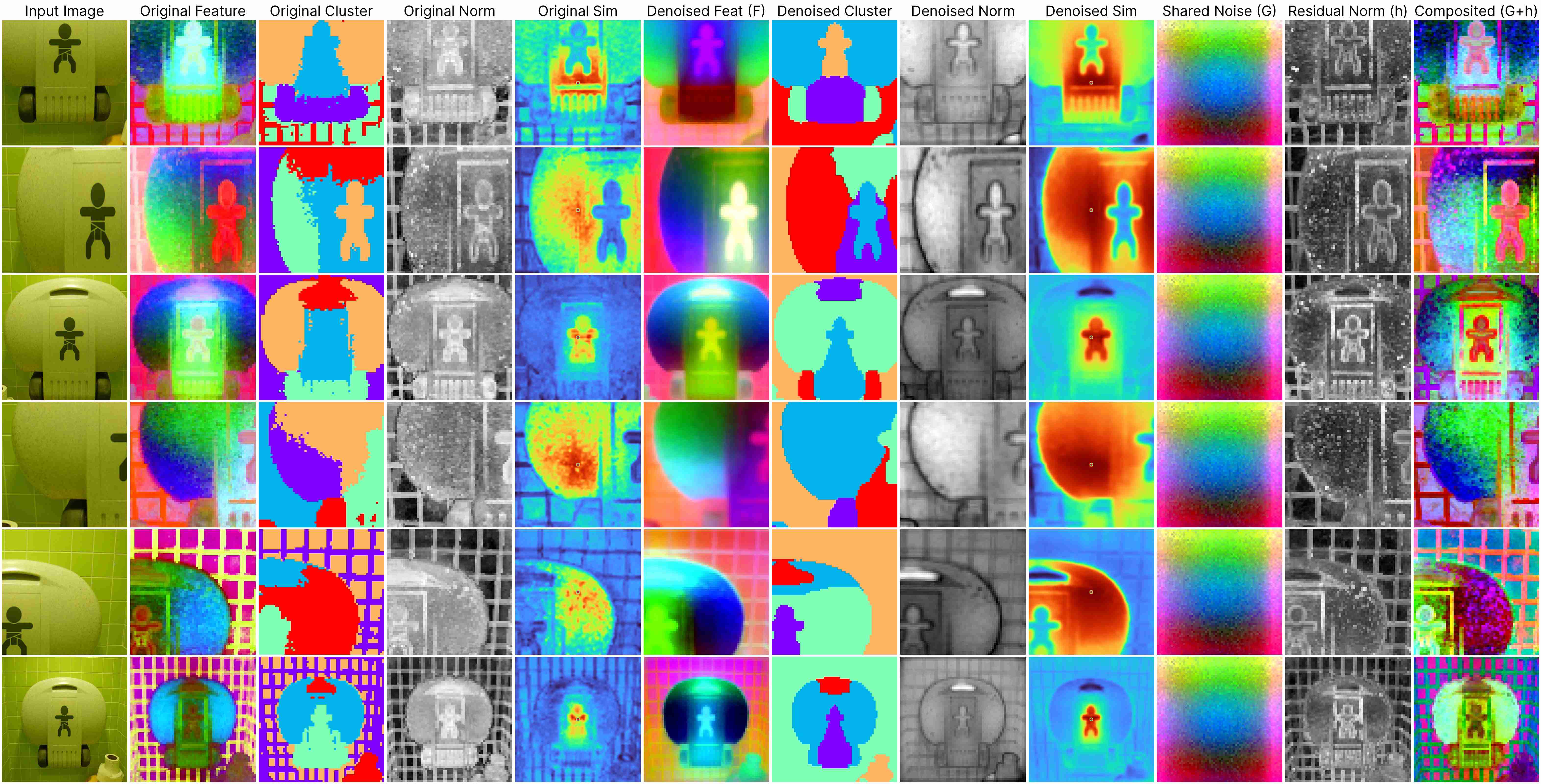
DINO ViT-Base (stride 8)



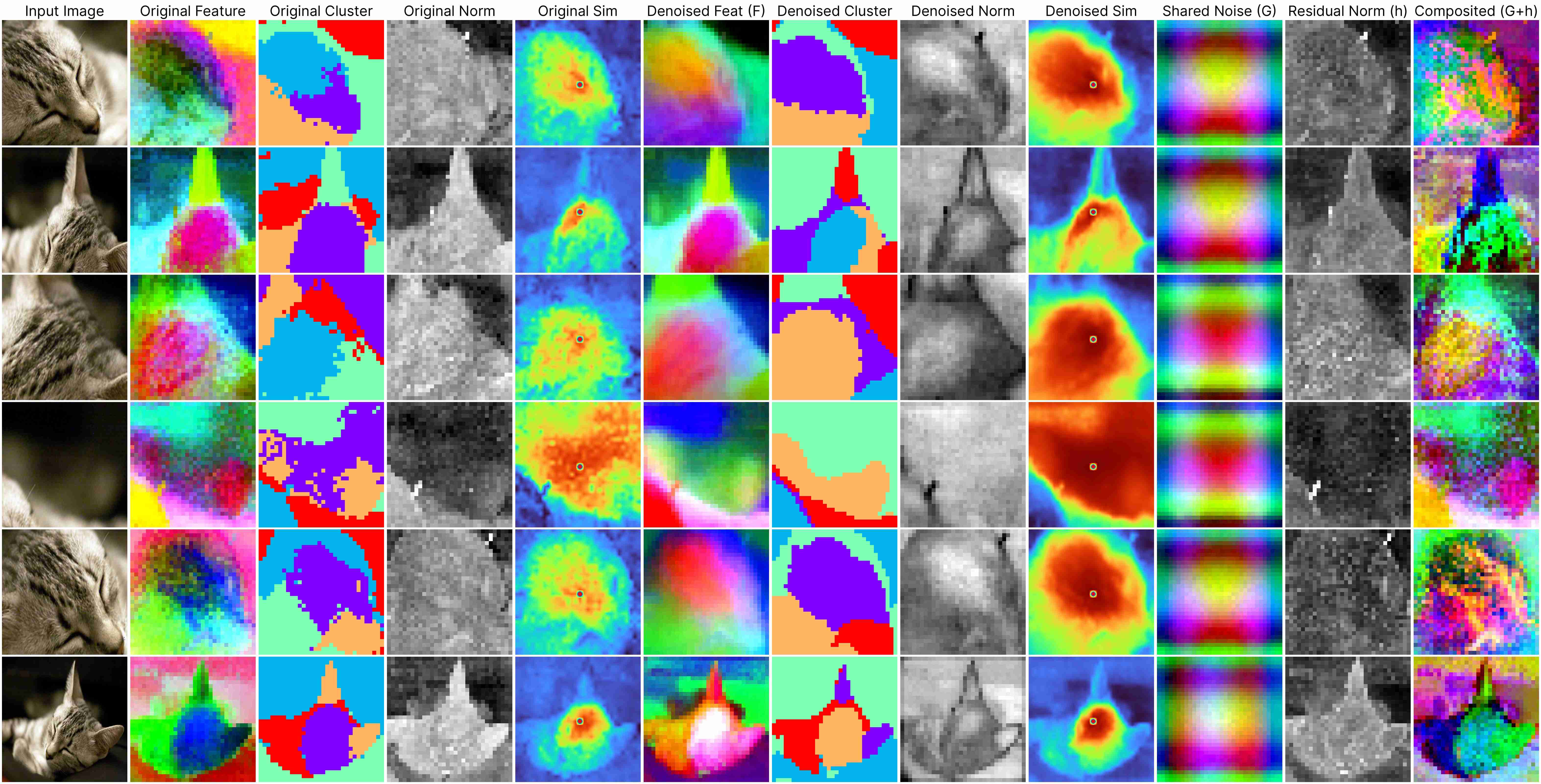
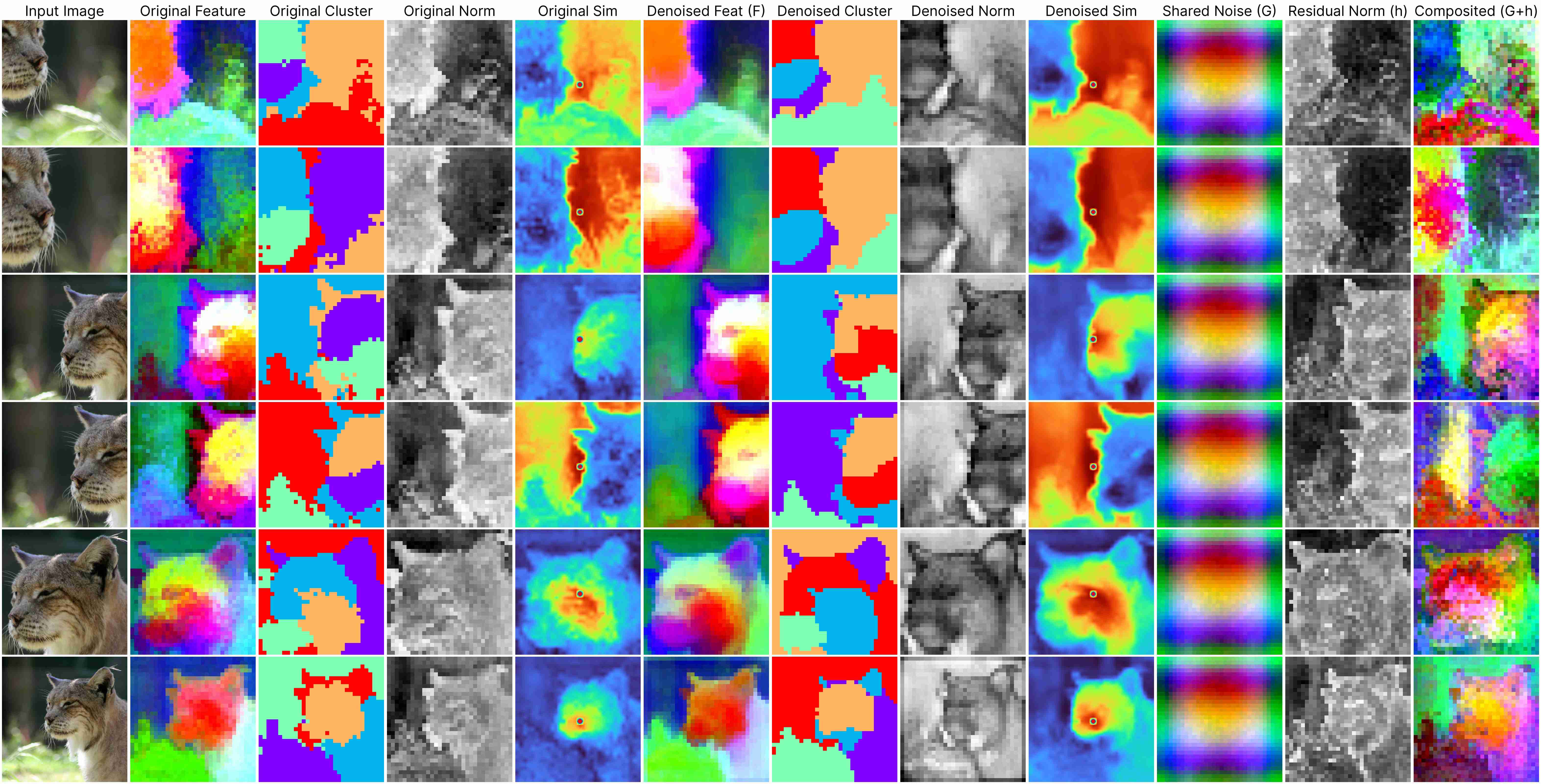

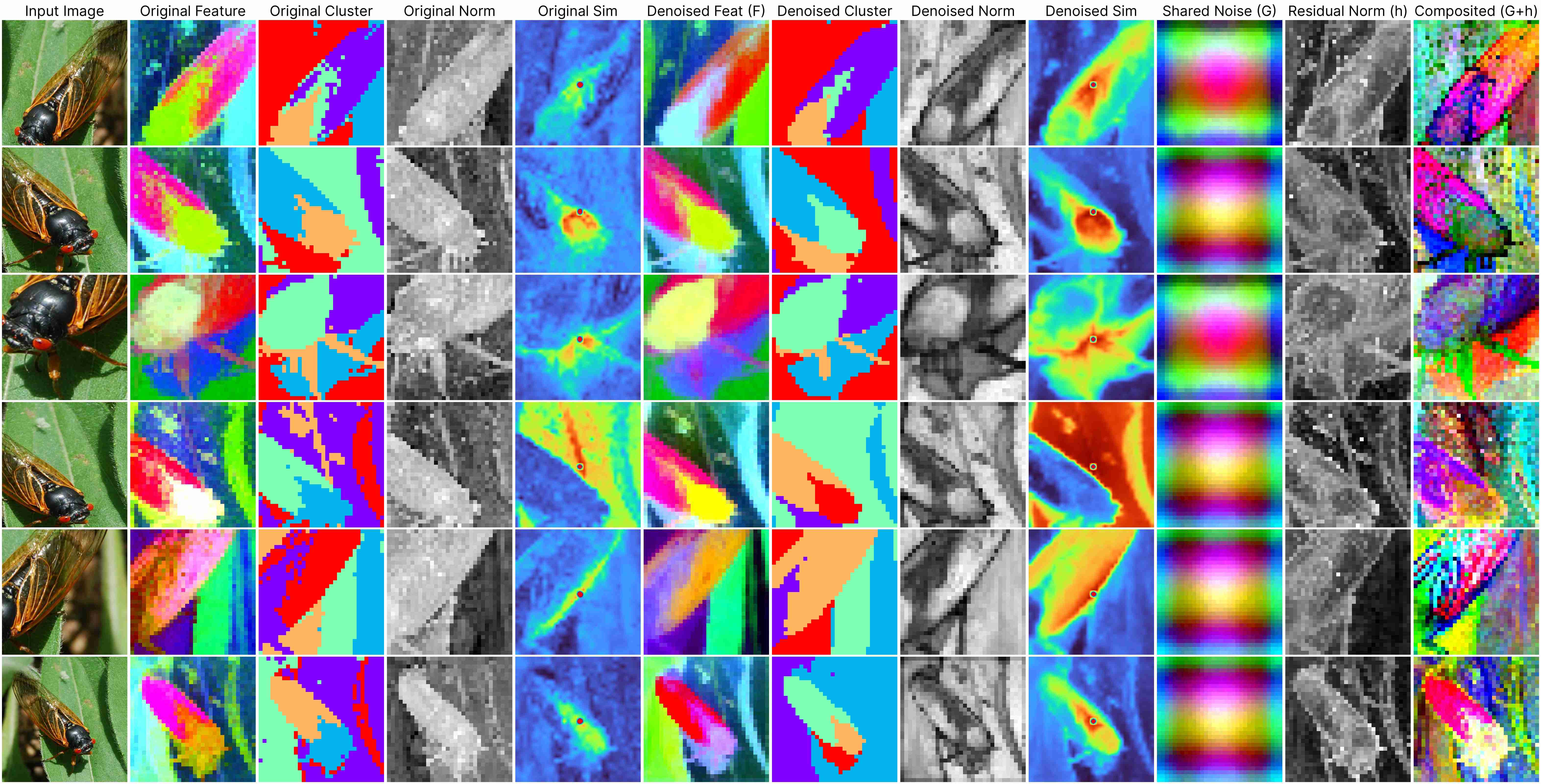




DINO ViT-Base (stride 16)
Our decomposition relies on this approximation:
ViT(x) ≈ F(x) + [G(position) + h(x, position)],
where: F(x) represents the denoised semantic features, G(position) denotes the shared artifacts across all views, and h(x, position) models the interdependency between position and semantic content.
DINOv1 has almost unnoticeable artifacts.
@article{yang2024denoising,
author = {Yang, Jiawei and Luo, Katie Z and Li, Jiefeng and Deng, Congyue and Guibas, Leonidas J. and Krishnan, Dilip and Weinberger, Kilian Q and Tian, Yonglong and Wang, Yue},
title = {DVT: Denoising Vision Transformers},
journal = {arXiv preprint arXiv:2401.02957},
year = {2024},
}