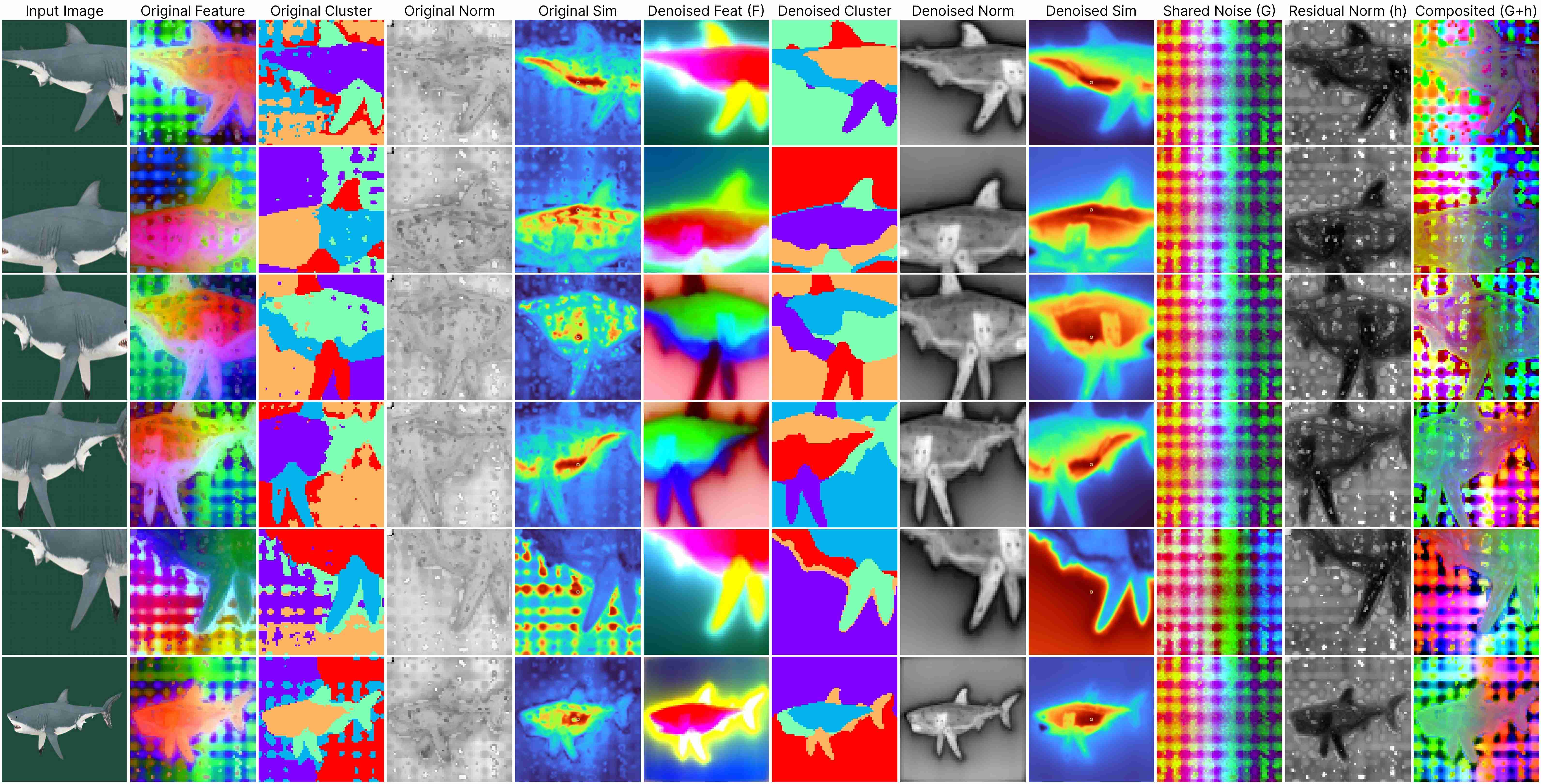
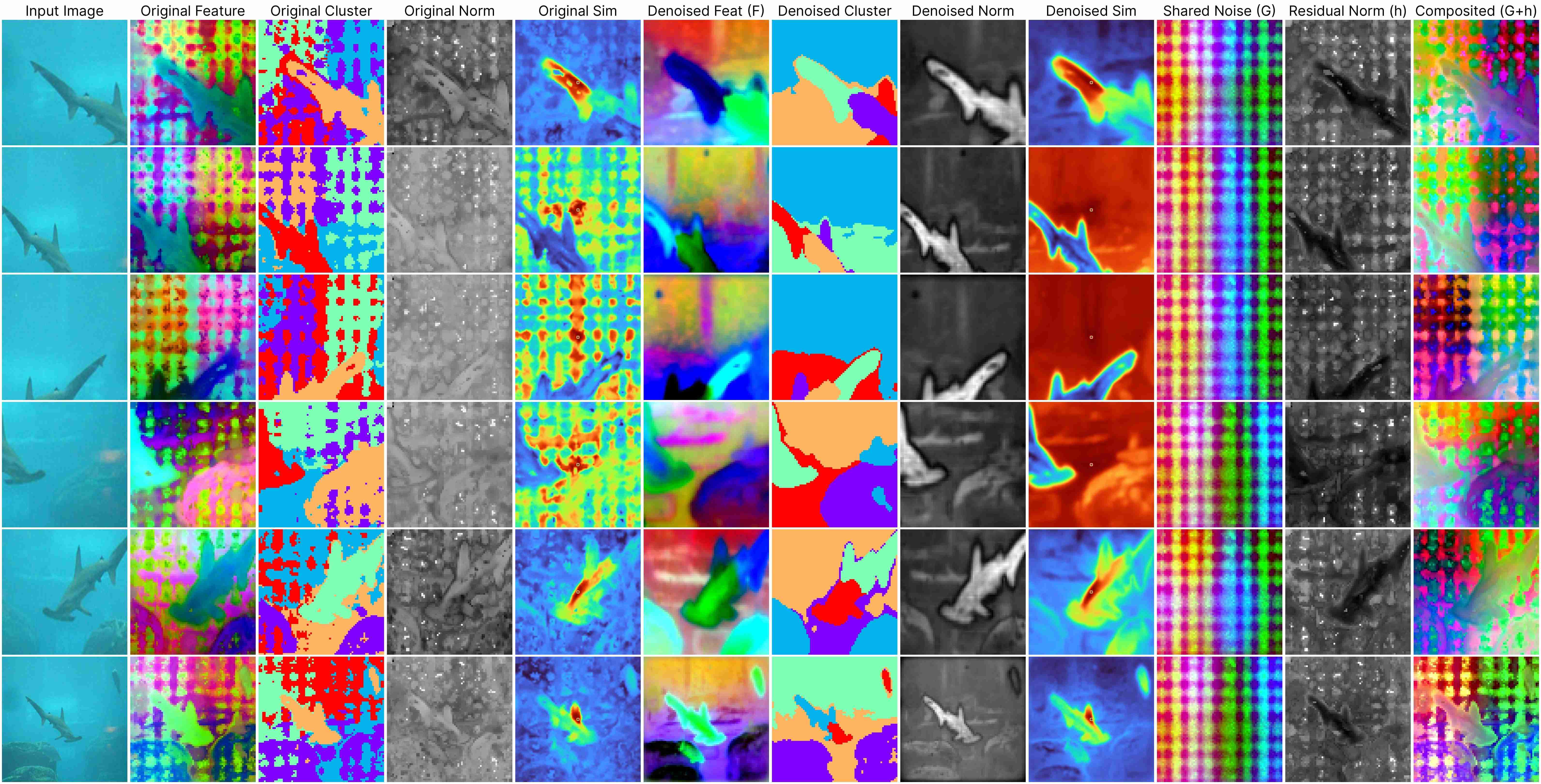

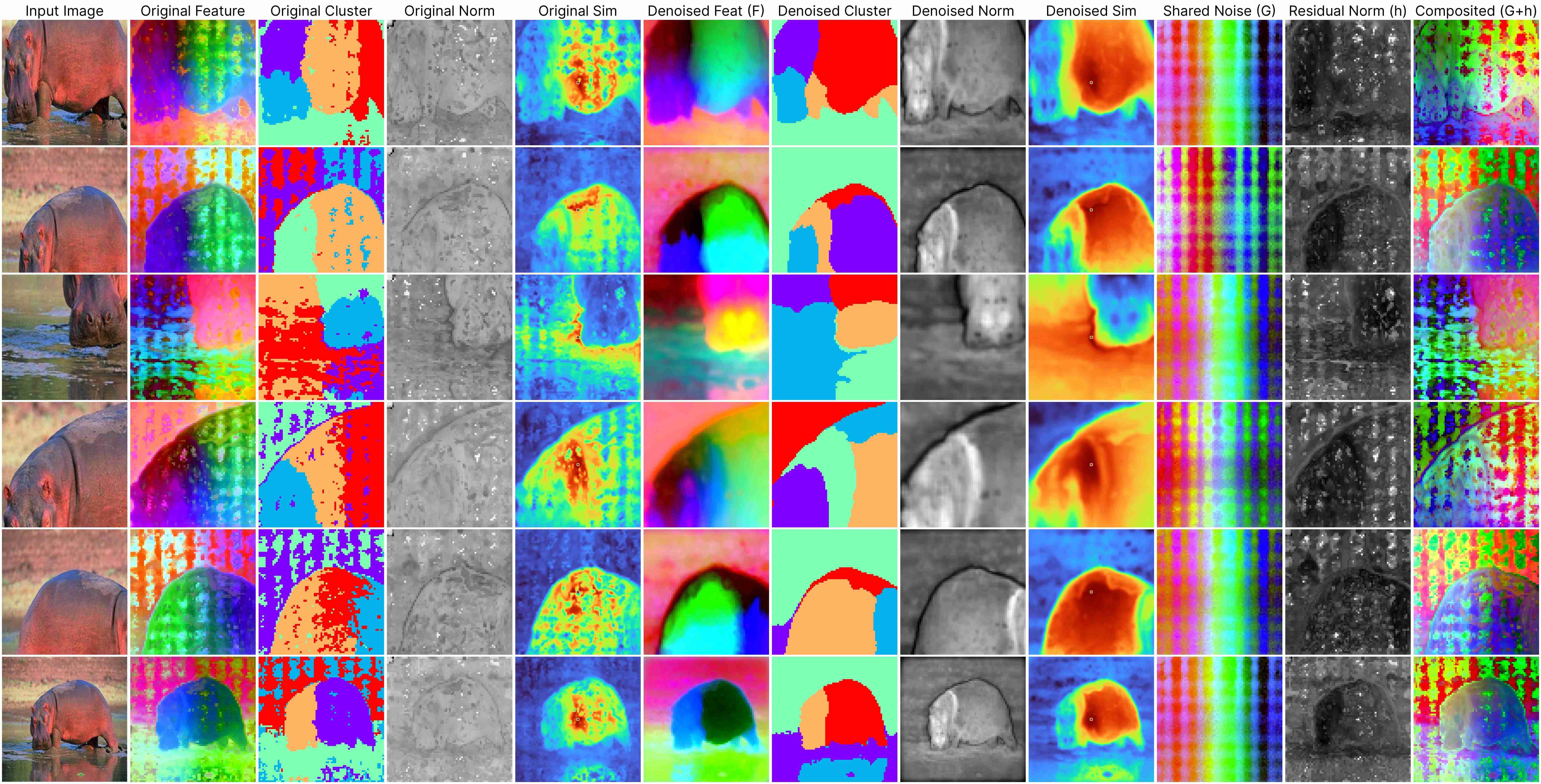
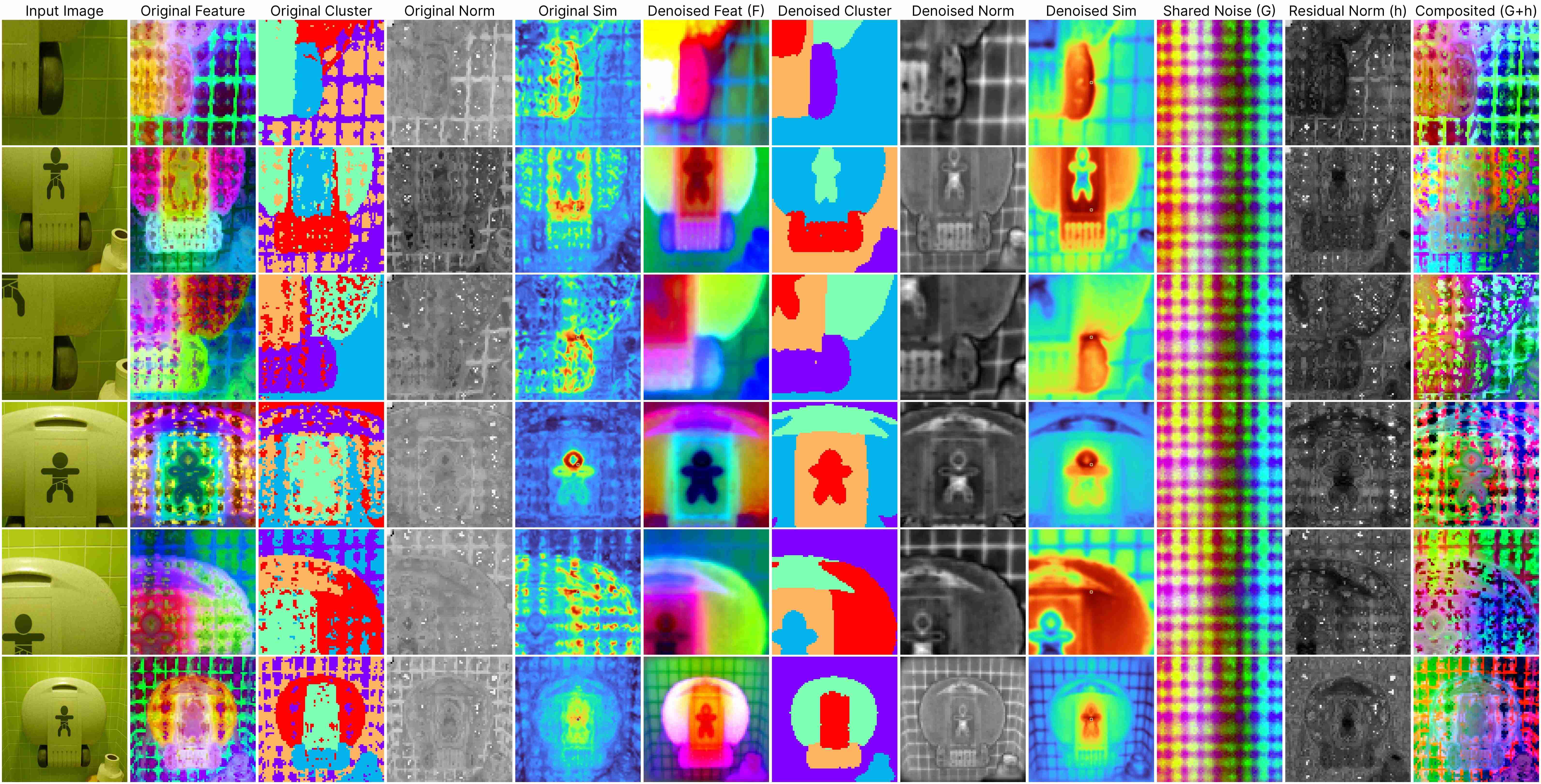
DINOv2 ViT-Base (stride 7)
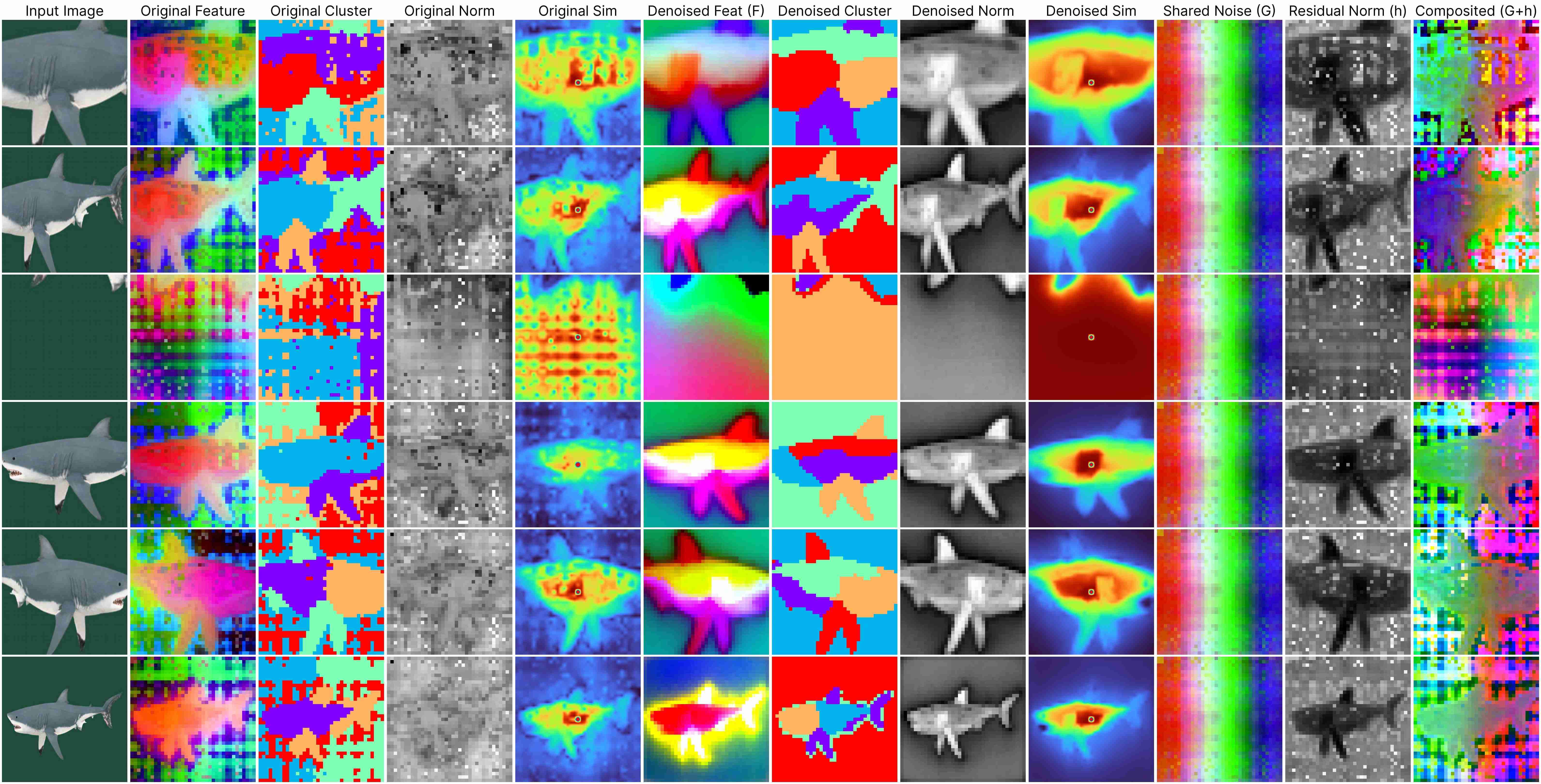

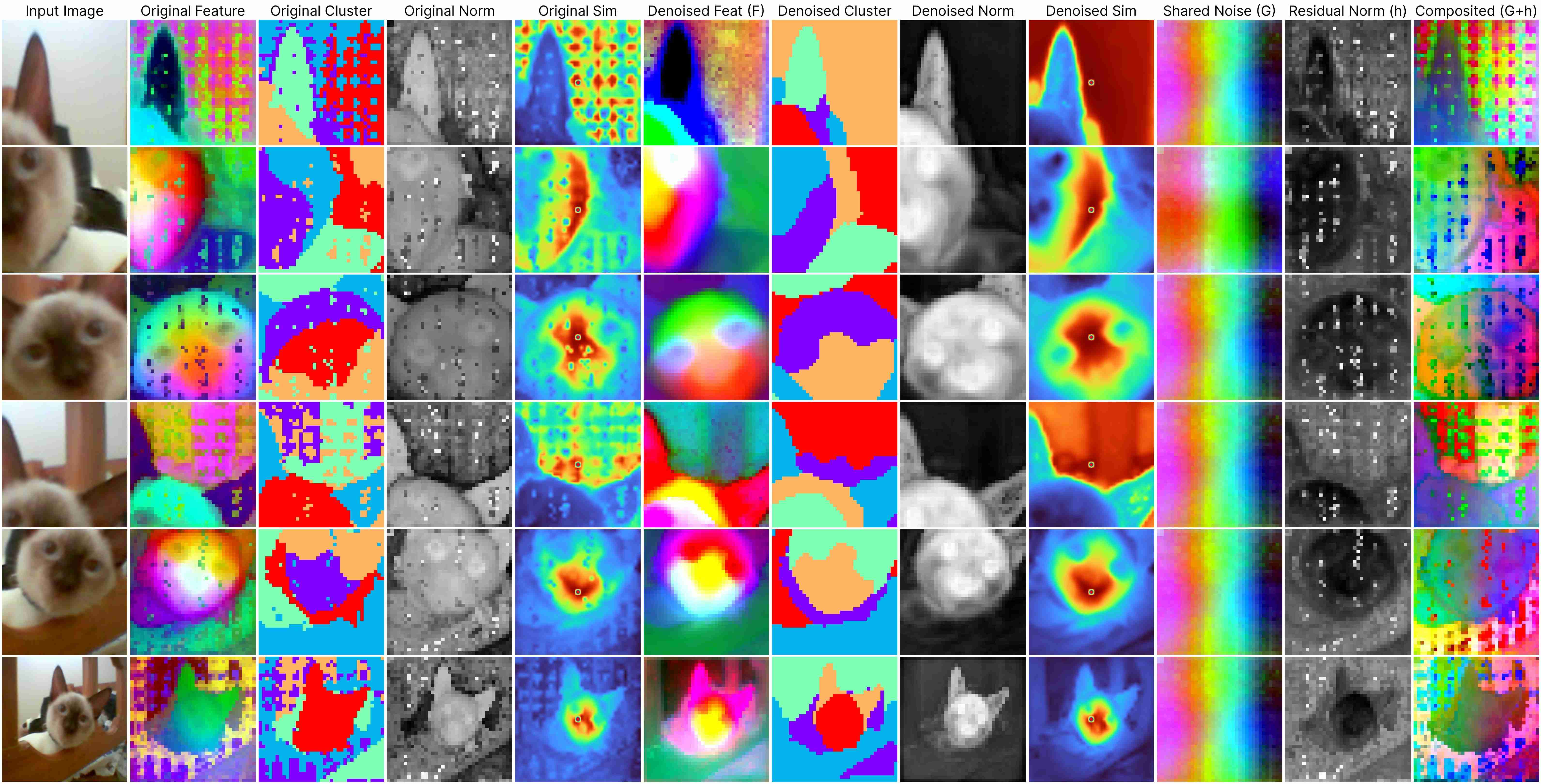
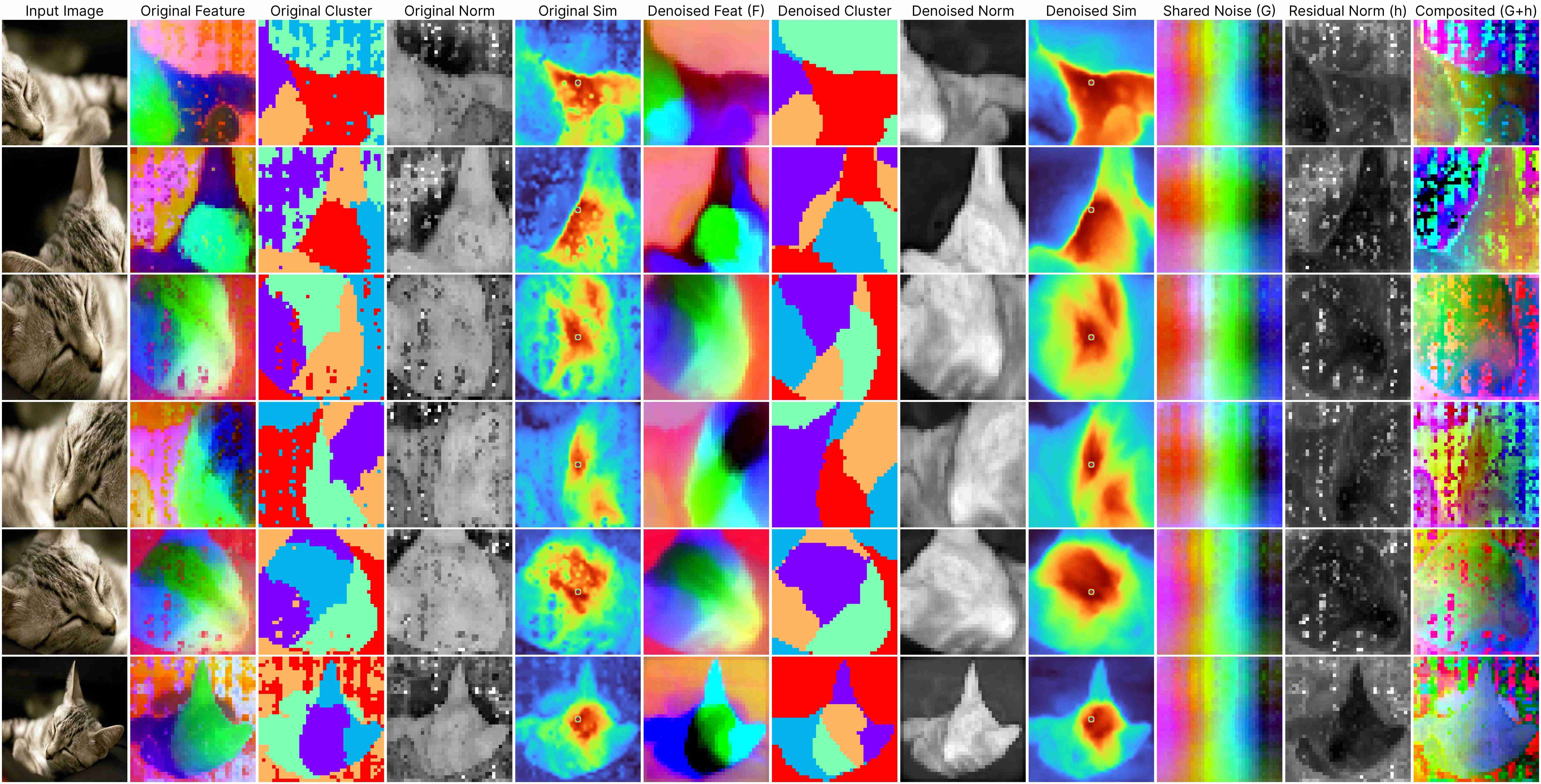


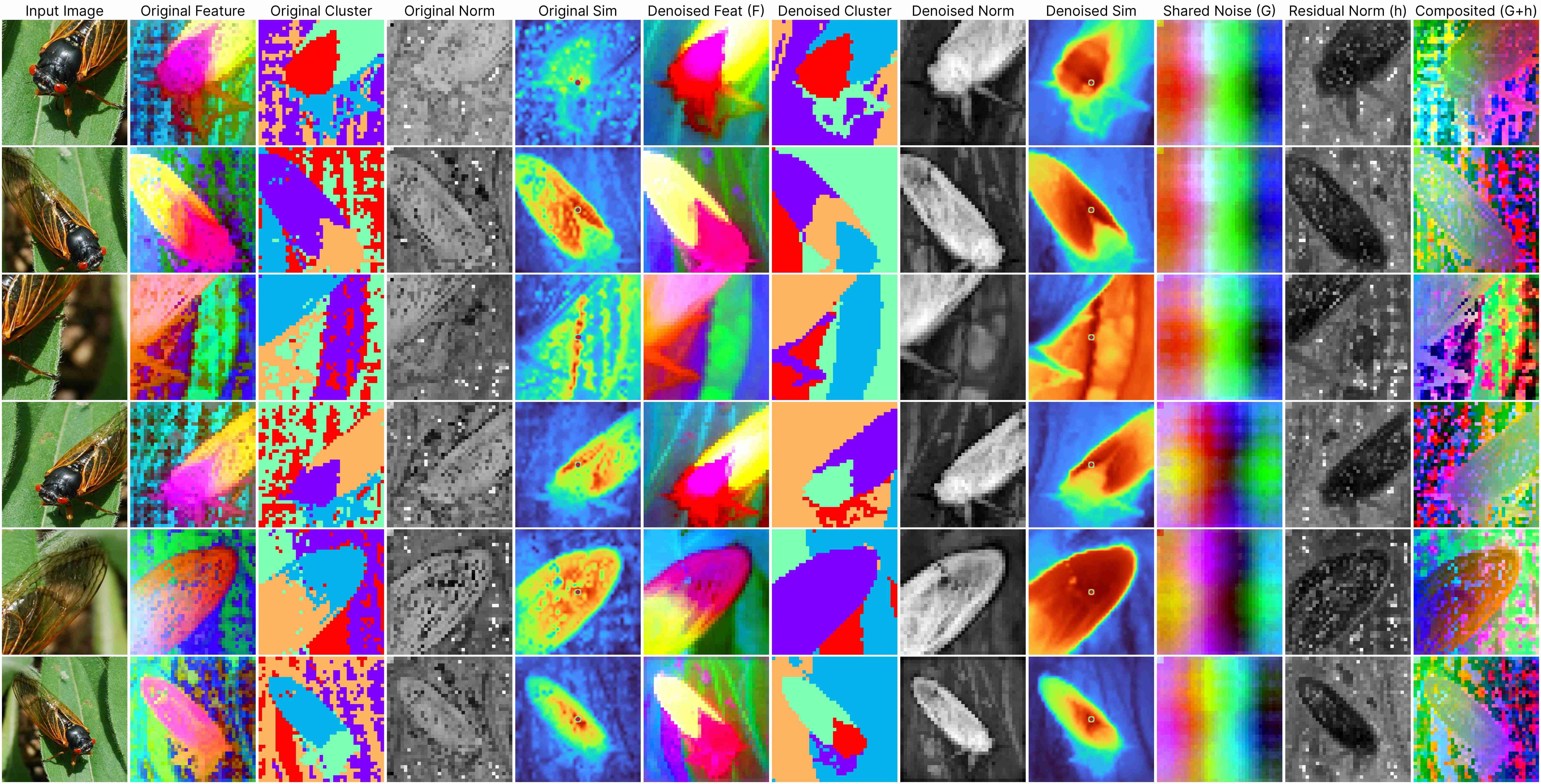
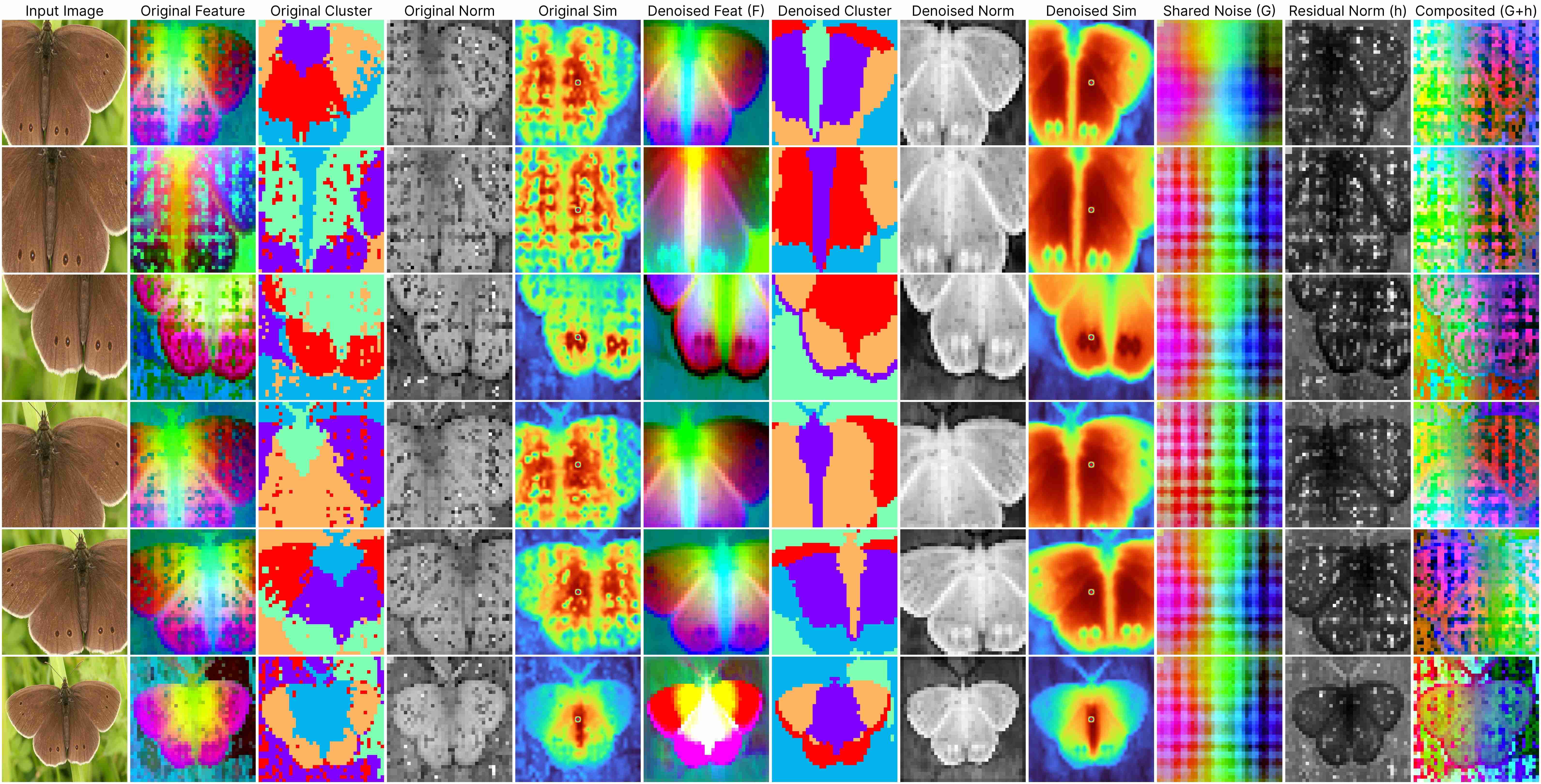
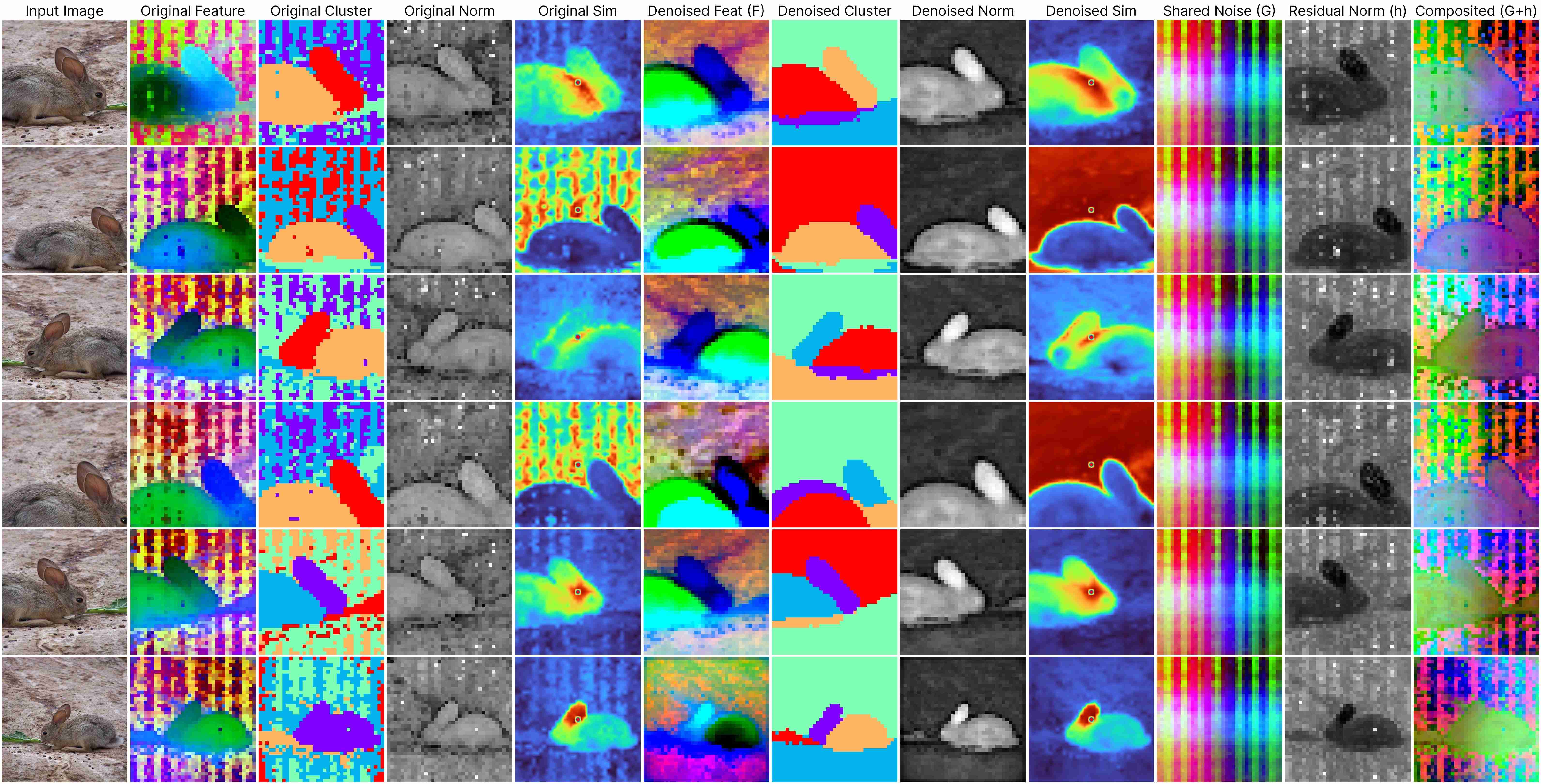
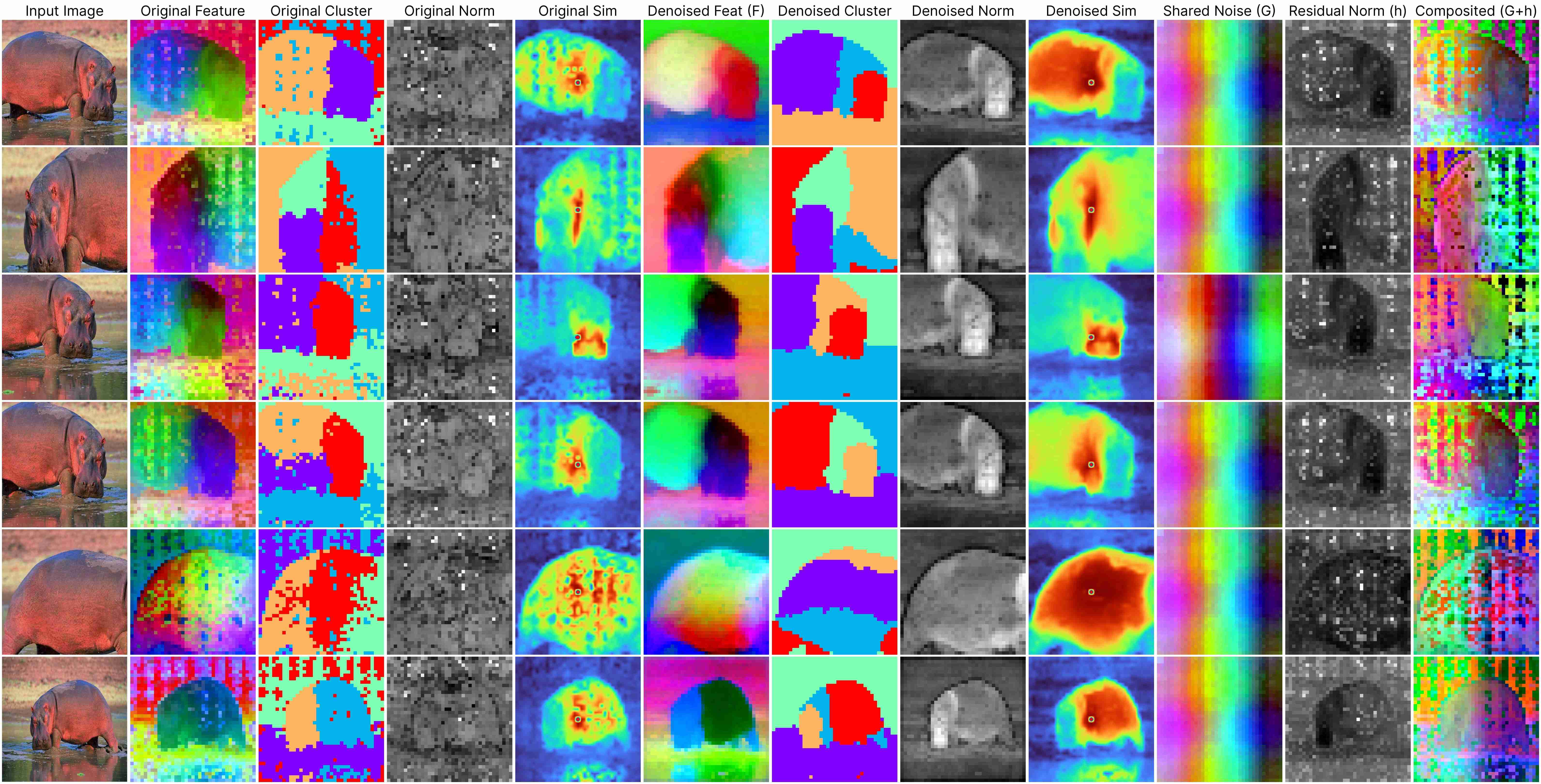
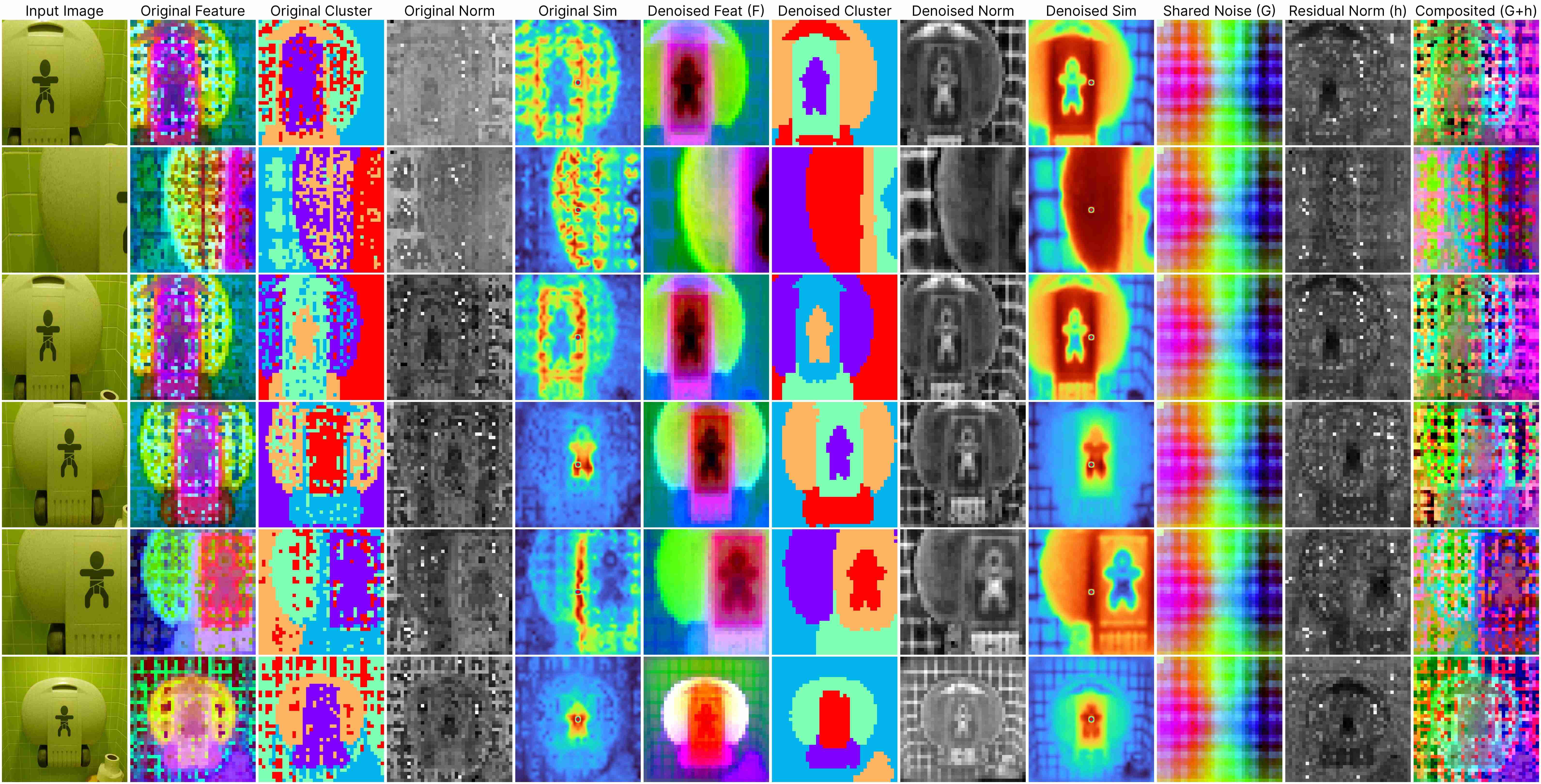
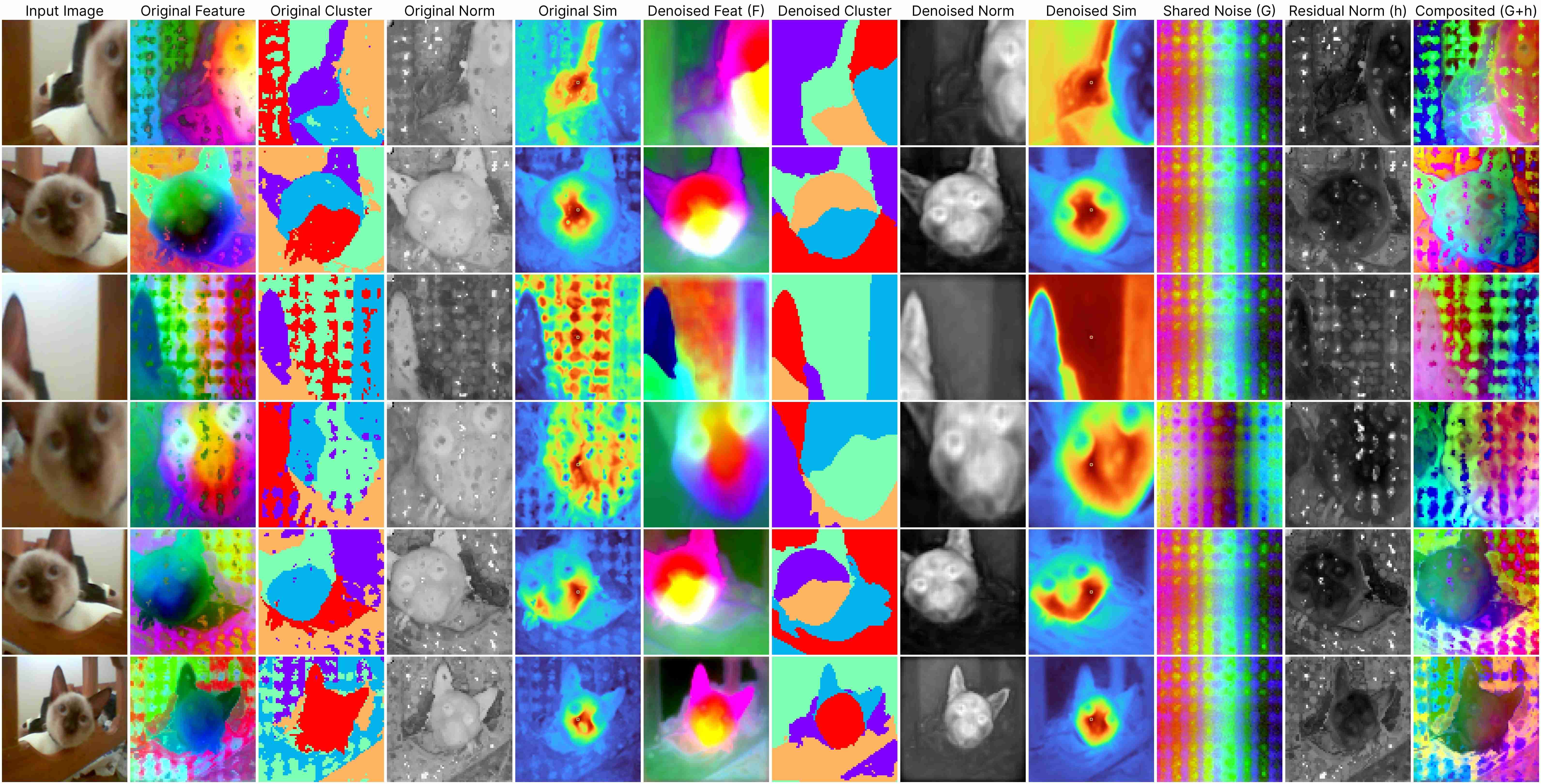
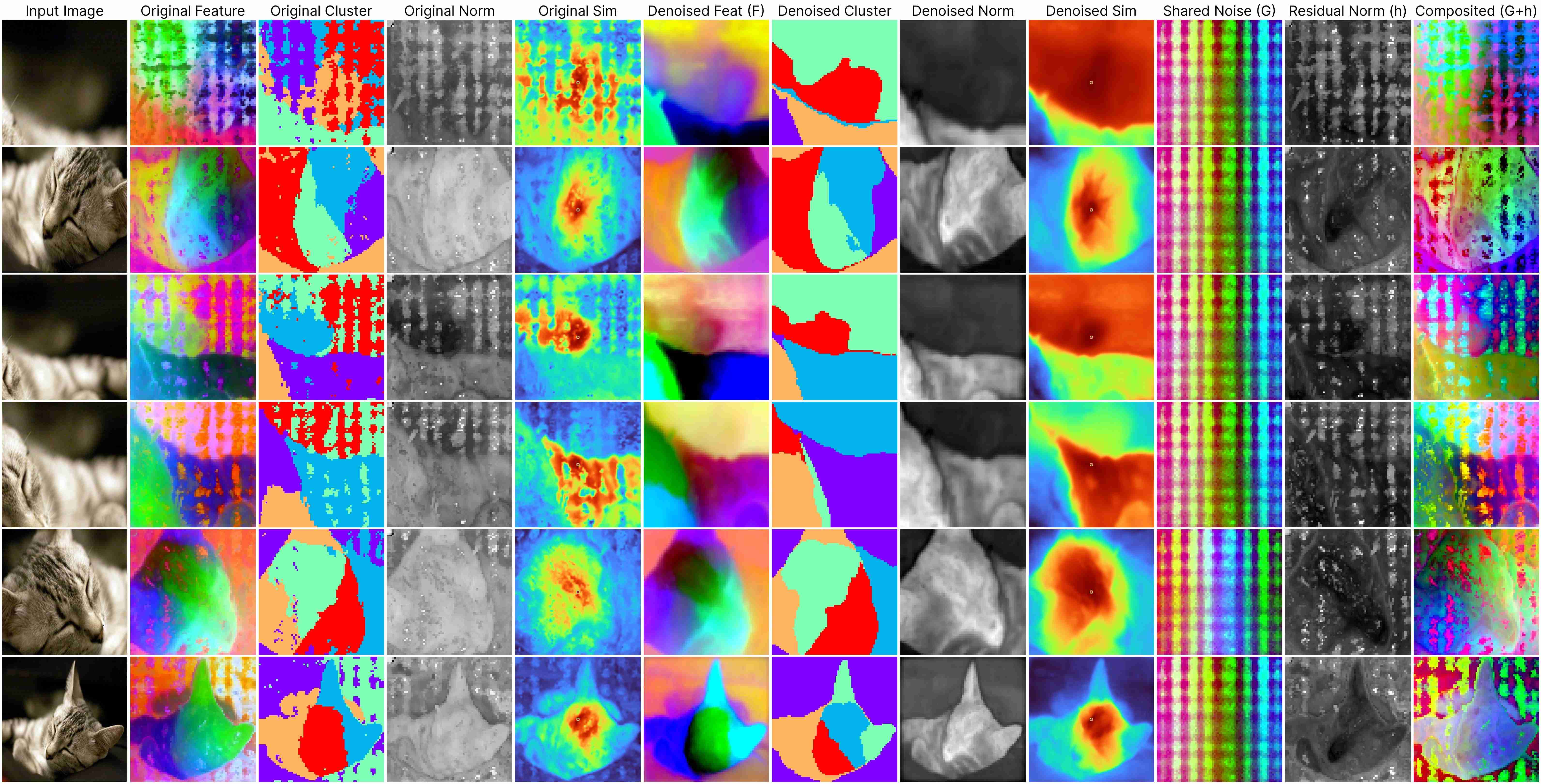
DINOv2 ViT-Base (stride 14)
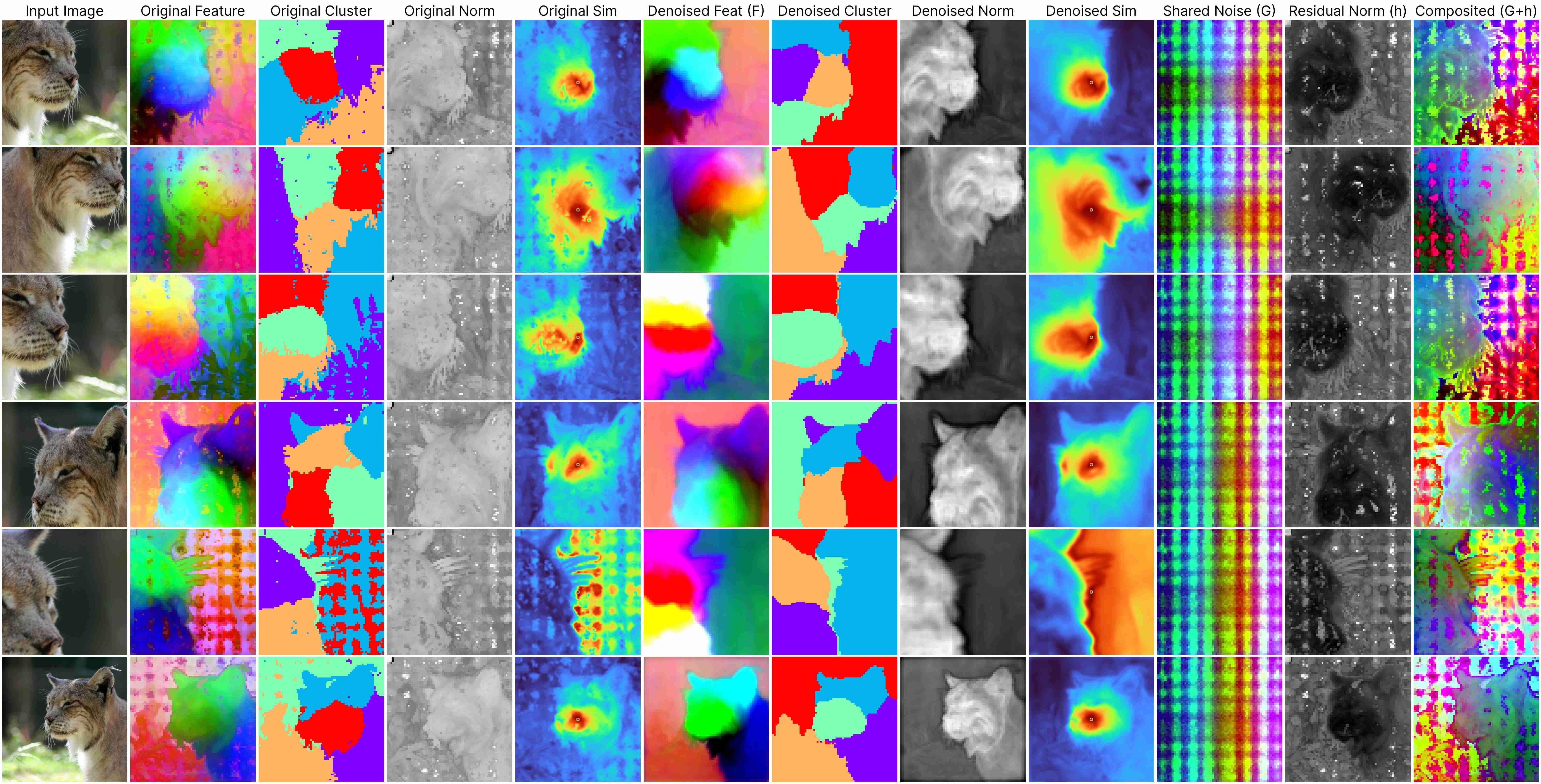
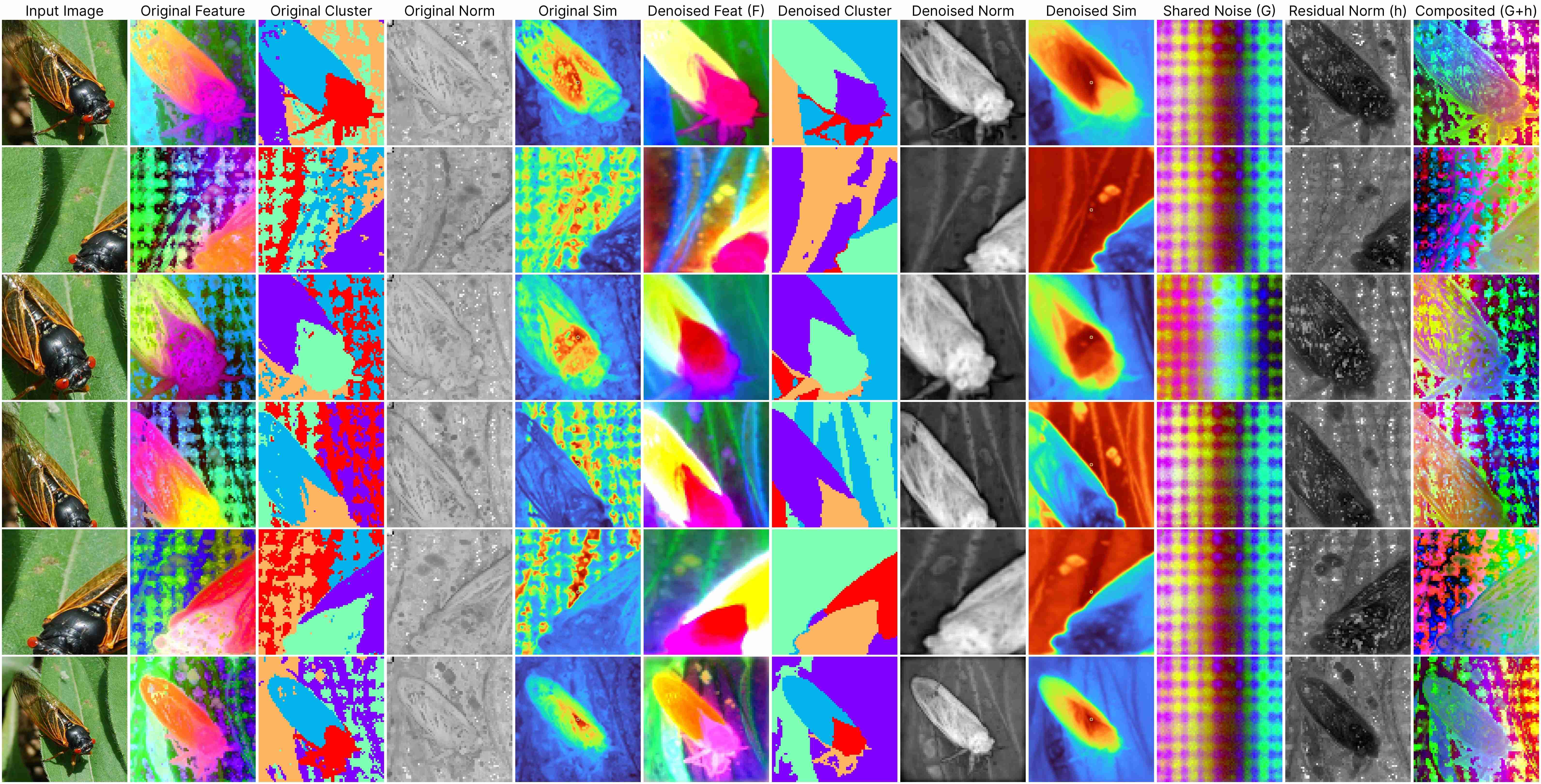
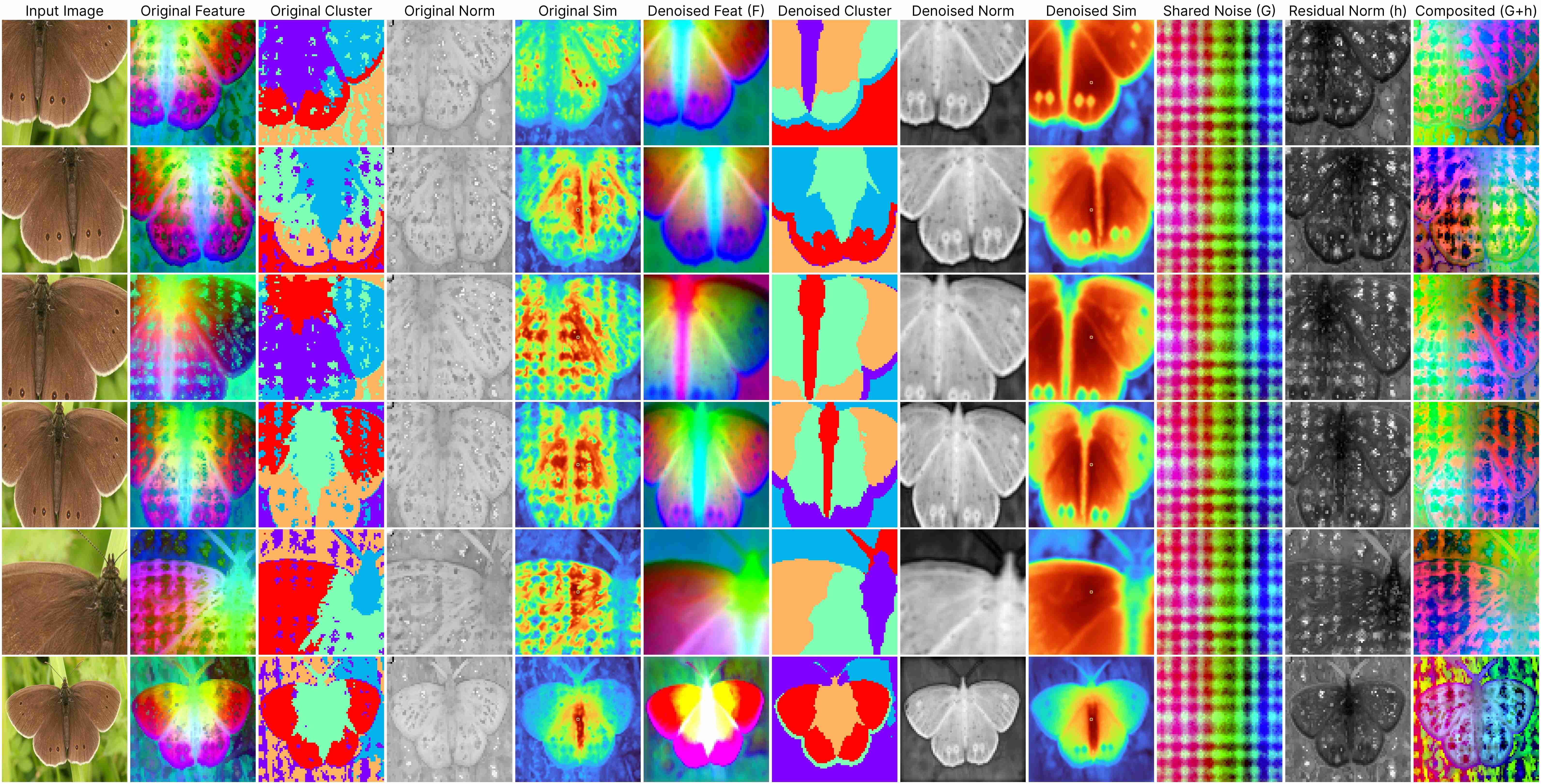
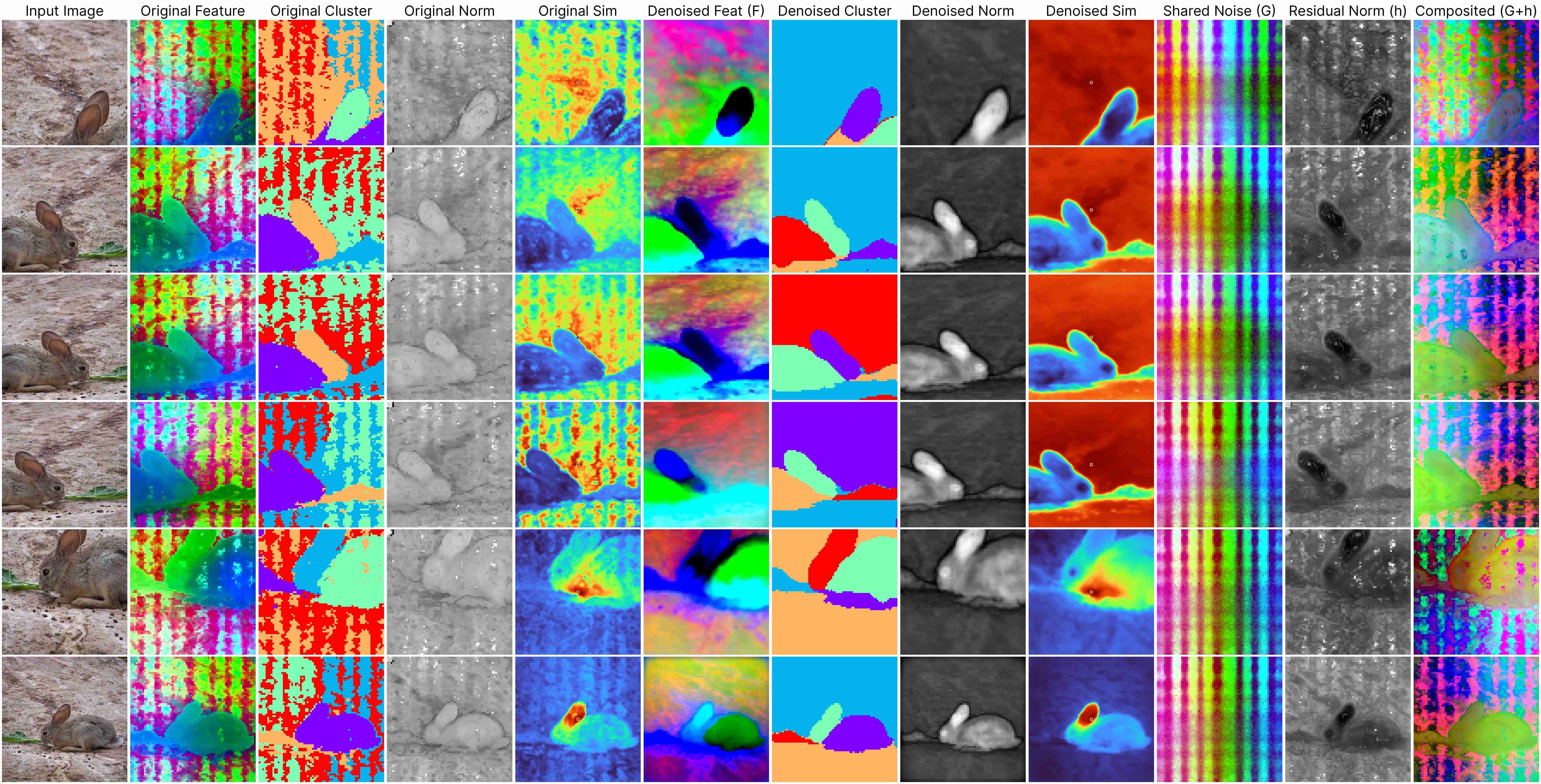
Our decomposition relies on this approximation:
ViT(x) ≈ F(x) + [G(position) + h(x, position)],
where: F(x) represents the denoised semantic features, G(position) denotes the shared artifacts across all views, and h(x, position) models the interdependency between position and semantic content.
Our method works for feature maps extracted under different stride size.
@article{yang2024denoising,
author = {Yang, Jiawei and Luo, Katie Z and Li, Jiefeng and Deng, Congyue and Guibas, Leonidas J. and Krishnan, Dilip and Weinberger, Kilian Q and Tian, Yonglong and Wang, Yue},
title = {DVT: Denoising Vision Transformers},
journal = {arXiv preprint arXiv:2401.02957},
year = {2024},
}