

DINOv2 ViT-Base (More models' results)
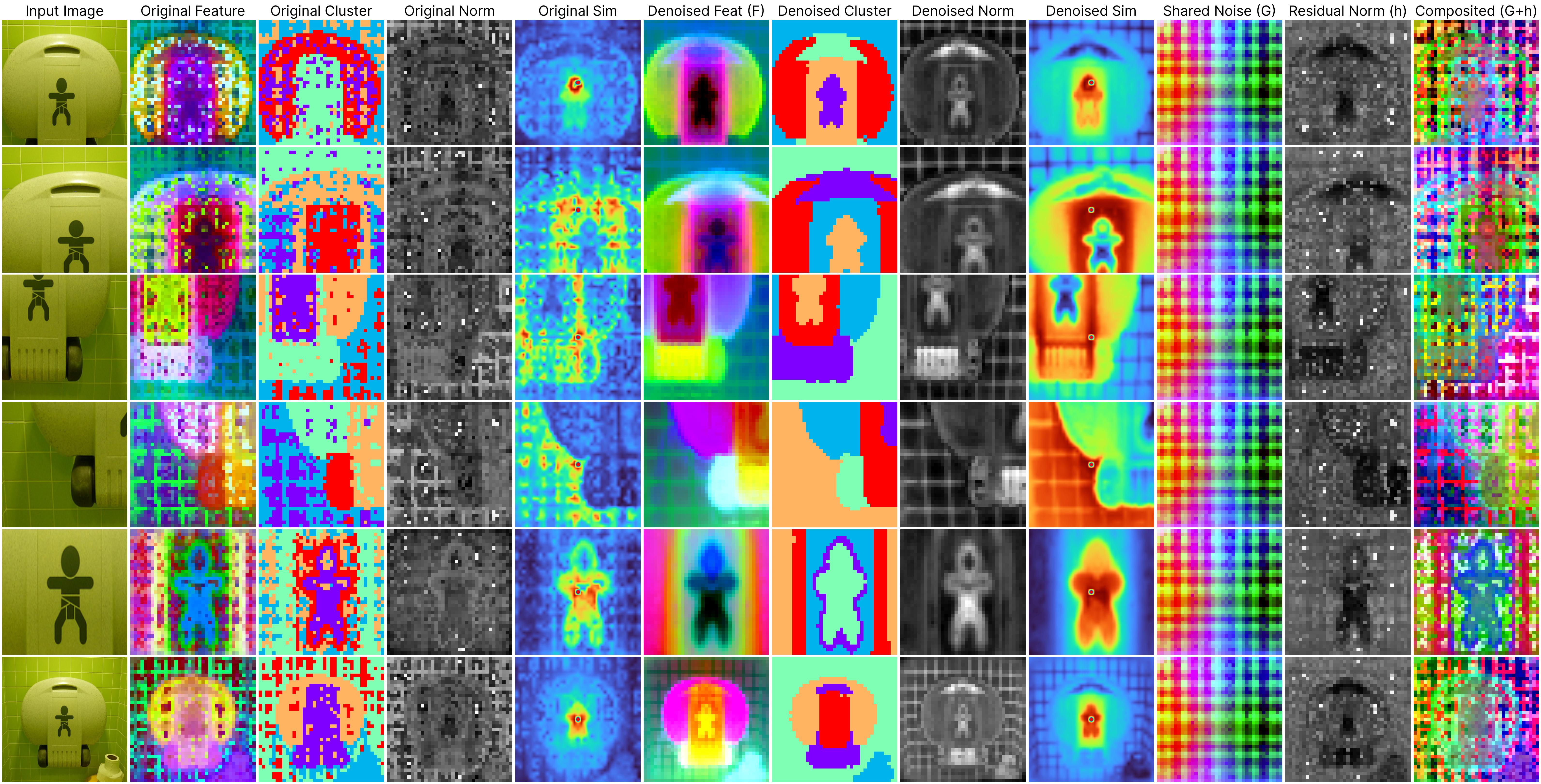
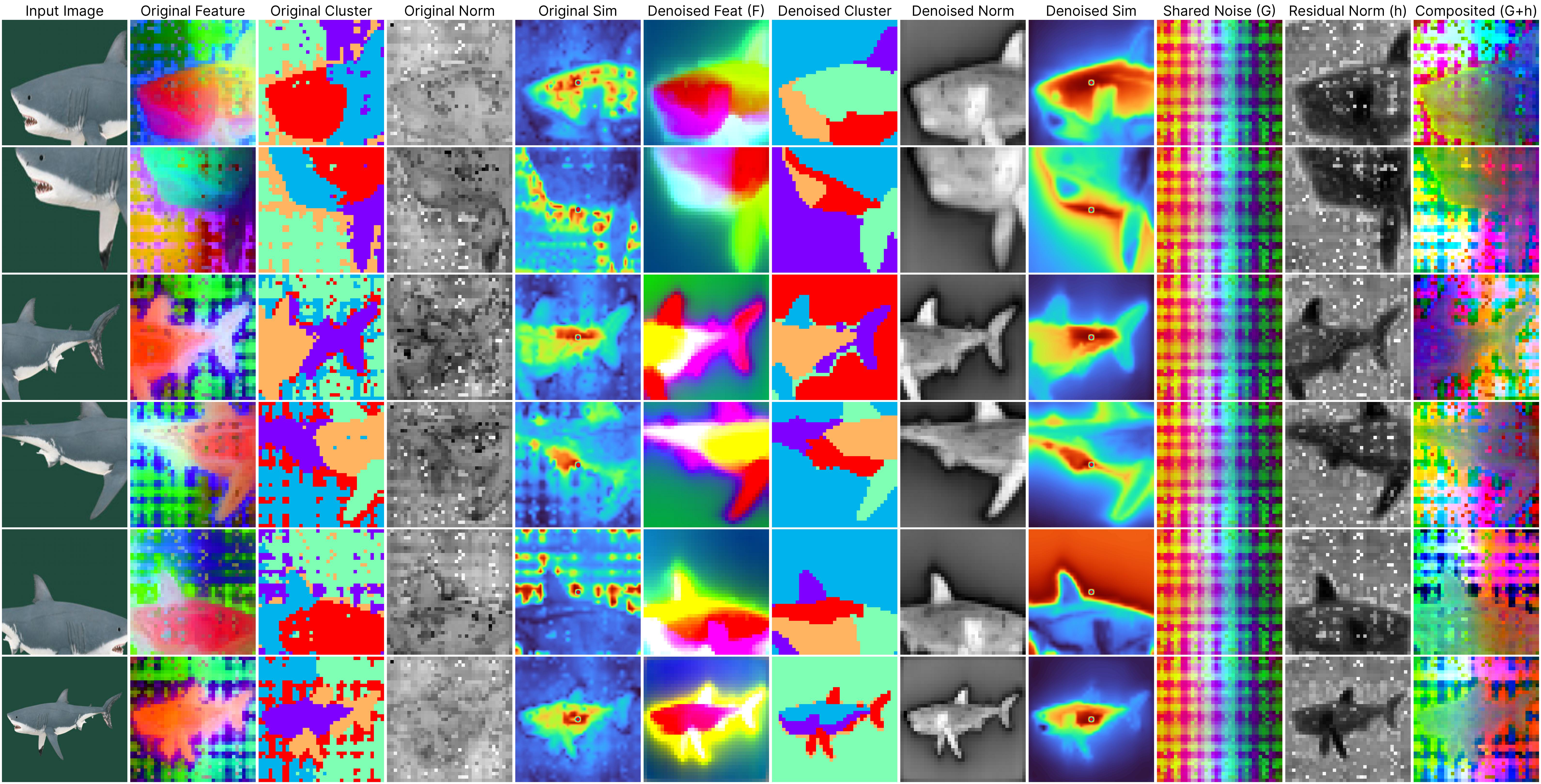
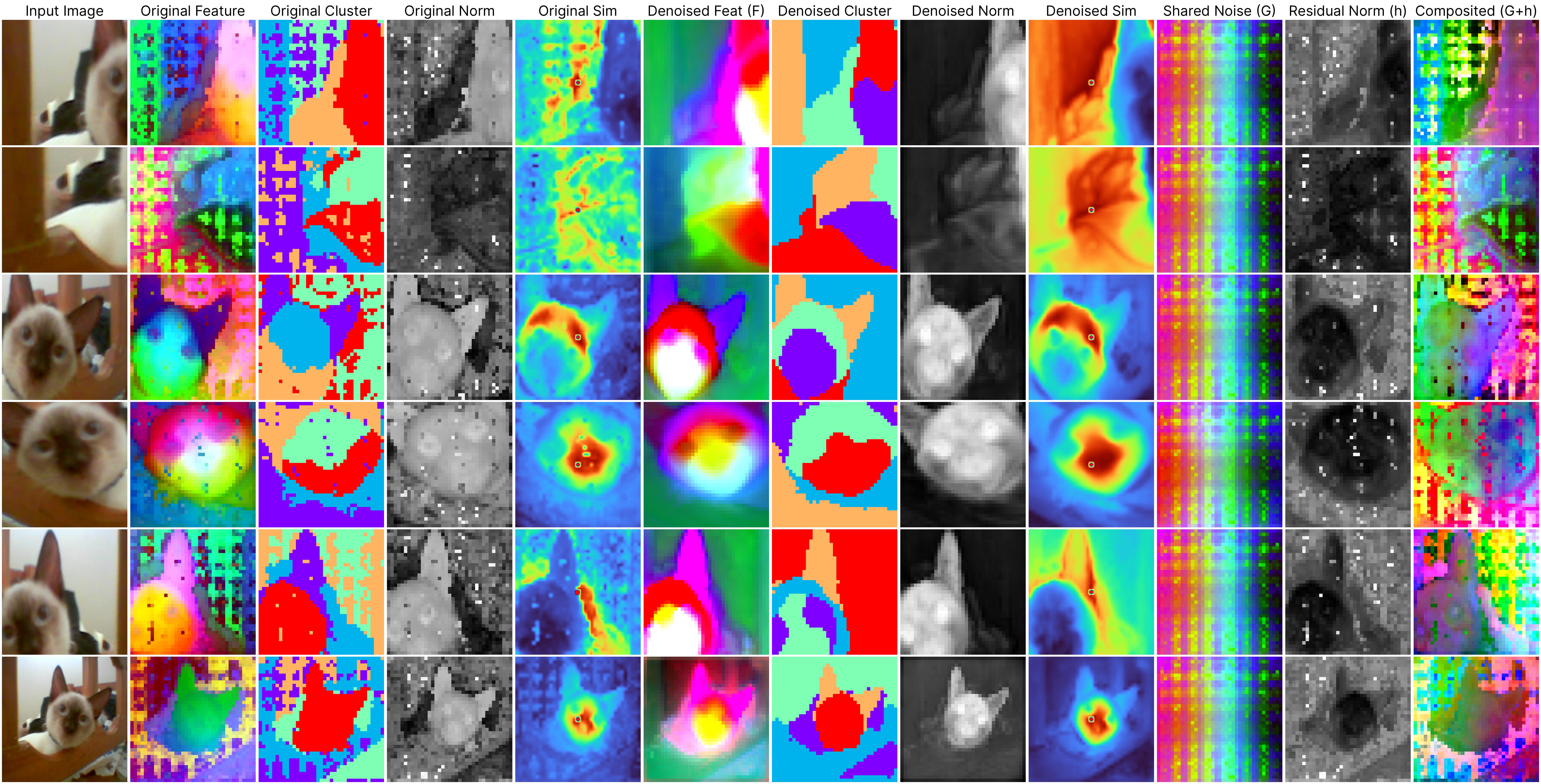
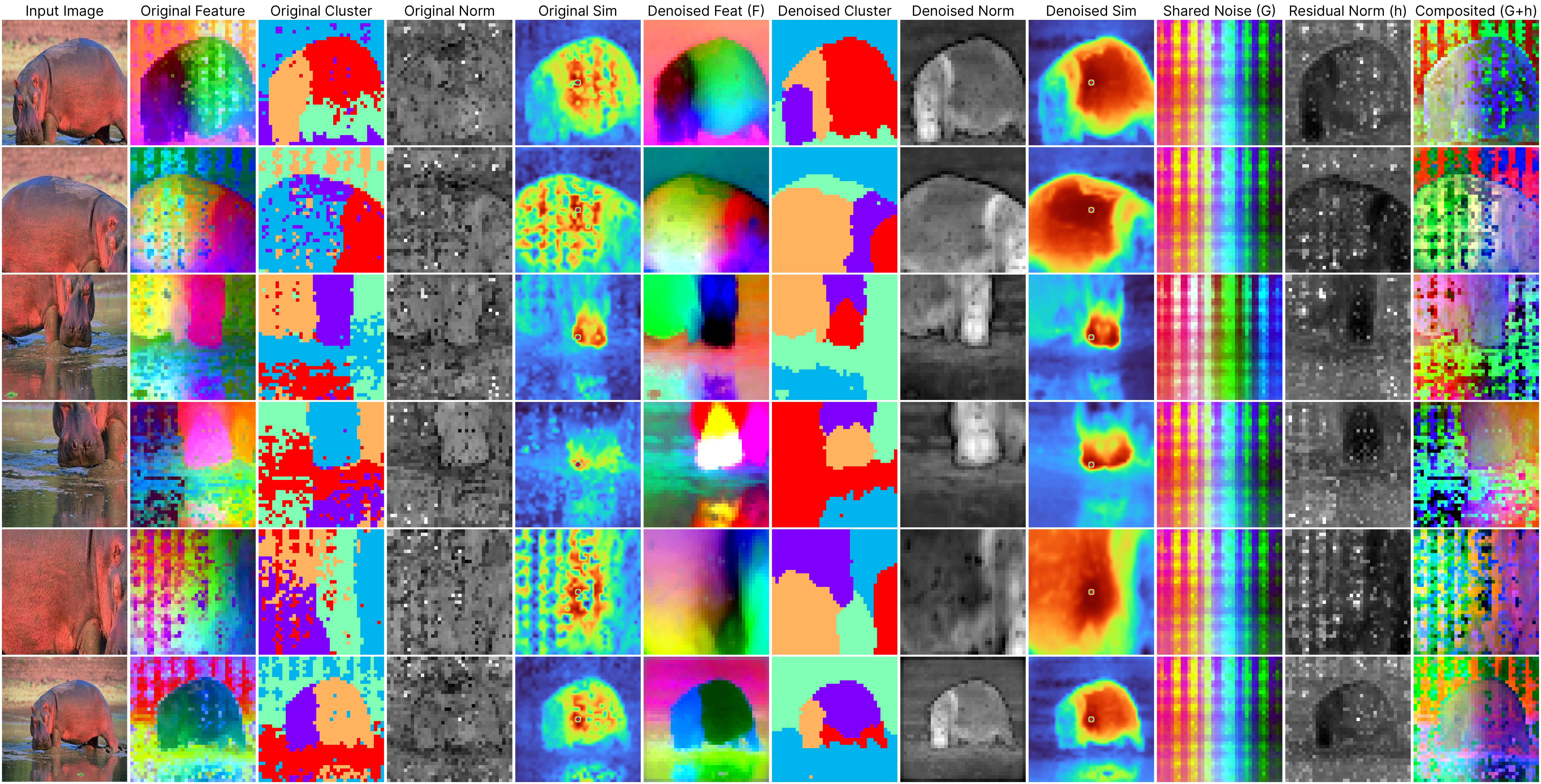
We study a crucial yet often overlooked issue inherent to Vision Transformers (ViTs): feature maps of these models exhibit grid-like artifacts (“Original features” in the teaser), which hurt the performance of ViTs in downstream dense prediction tasks such as semantic segmentation, depth prediction, and object discovery. We trace this issue down to the positional embeddings at the input stage. To mitigate this, we propose a two-stage denoising approach, termed Denoising Vision Transformers (DVT). In the first stage, we separate the clean features from those contaminated by positional artifacts by enforcing cross-view feature consistency with neural fields on a per-image basis. This per-image optimization process extracts artifact-free features from raw ViT outputs, providing clean feature estimates for offline applications. In the second stage, we train a lightweight transformer block to predict clean features from raw ViT outputs, leveraging the derived estimates of the clean features as supervision. Our method, DVT, does not require re-training the existing pre-trained ViTs, and is immediately applicable to any Vision Transformer architecture. We evaluate our method on a variety of representative ViTs (DINO, DeiT-III, EVA02, CLIP, DINOv2, DINOv2-reg) and demonstrate that DVT consistently improves existing state-of-the-art general-purpose models in semantic and geometric tasks across multiple datasets (Fig. 1, right, Tabs. 2 to 4). We hope our study will encourage a re-evaluation of ViT design, especially regarding the naive use of positional embeddings. Our code and checkpoints are publicly available.
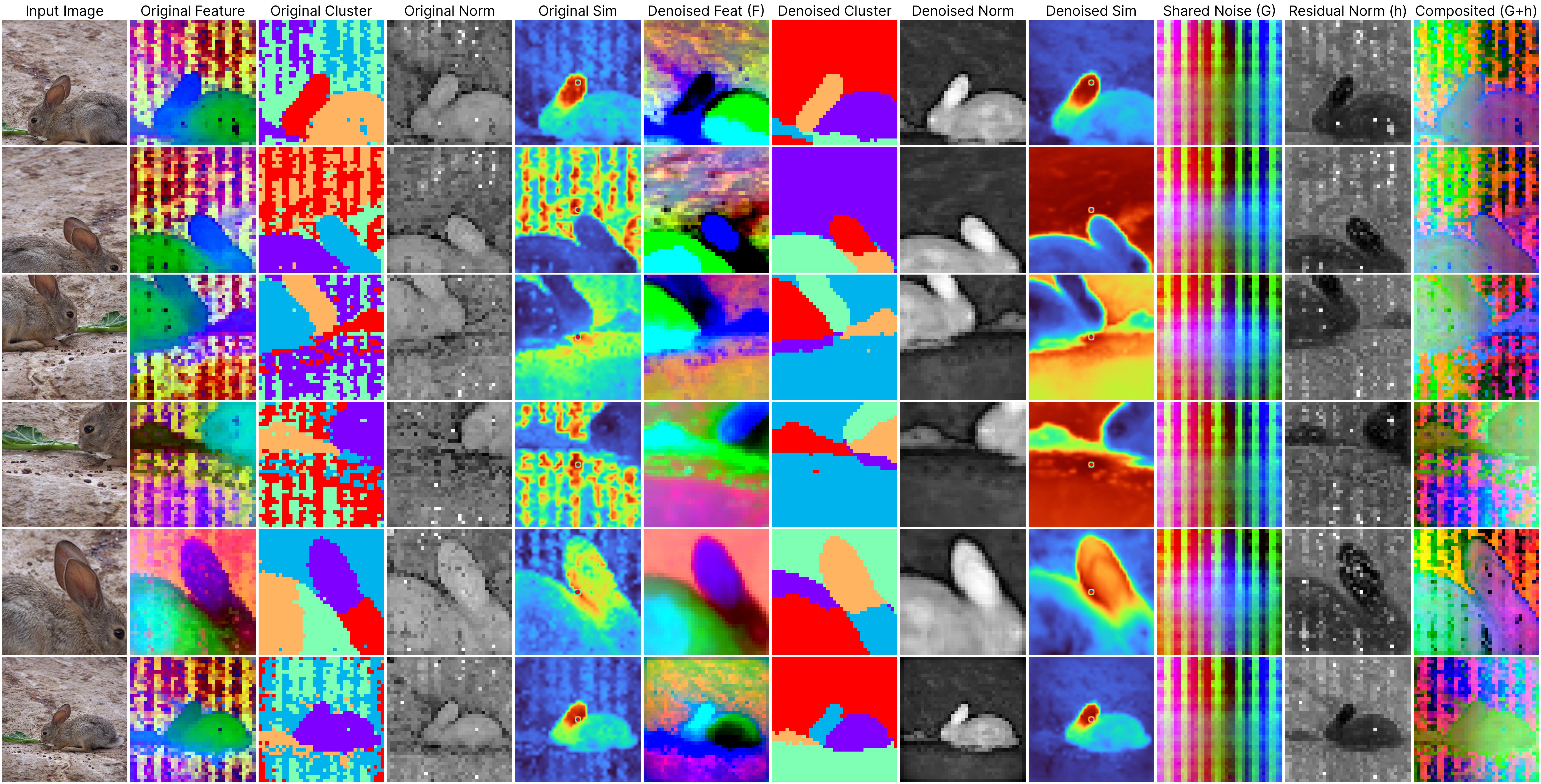
Despite the significant strides made by ViTs, our work reveals a crucial yet often overlooked challenge: the presence of persistent noise artifacts in ViT outputs, observable across various training algorithms. These artifacts not only compromise visual clarity but also hinder feature interpretability and disrupt semantic coherence. For example, the below examples (2nd to 4th columns) demonstrate that applying clustering algorithms directly on the raw ViT output results in noisy clusters, and the patch feature similarity is less reliable.
Jump to the method section to understand what each column means.
DINOv2 ViT-Base (More models' results)
We empirically identify several properties that may be hidden in the original DINOv2 model but are revealed in our denoised version.
First, we collect features from randomly sampled images from the DAVIS dataset and compute a global PCA reduction matrix to map high-dimensional features to three-dimensional color values. This reduction matrix is then applied to the features of the denoised DINOv2 model.
For visualizations of the PCA results, refer to (h) for 3-channel visualizations and to (c), (d), and (e) for individual PCA components. These components highlight different aspects of the image, with the second component capturing the object's prominence. We thus use it as a foreground mask to separate the object from the background and visualize the foreground's PCA feature map separately in (b). This foreground disentanglement is not observed in the first three principal components of the original DINOv2 model. Following this, we examine up to 10 PCA components and find the 5th component to be the most informative, though still noisy, for the object (check out this). It is arguably unfair for us to directly compare against these noisy foreground objects. Therefore, we use the officially provided `standard_array` to compute the foreground mask for the original DINOv2 model. However, it remains unclear how this `standard_array` is generated. We also provide the foreground PCA results by relying on the 5th PCA component for reference.
Additionally, as discussed in the paper, the feature norm of the denoised features can also serve as an object indicator. We visualize these feature norms in (h), noting how they complement the PCA results. Lastly, we visualize the KMeans clustering results of the denoised features in (g) to show how the features are clustered in the feature space.
The same procedure is applied to the original DINOv2 model for comparison. We find that the top 3 PCA components of the original DINOv2 model do not capture the object's prominence as well as the denoised DINOv2 model. They mainly indicate the positional patterns. The feature norm of the original DINOv2 model also does not serve as a good object indicator. The KMeans clustering results of the original DINOv2 model are adversely affected by the noise in the features.
*All results are derived from our generalizable denoiser (to be released) applied to unseen frames during denoiser training.(a) Input
(b) Foreground PCA (*ref)
(c) 1st Component of Feature PCA
(d) 2nd Component of Feature PCA
(e) 3rd Compont of Feature PCA
(f) Feature Norm
(g) KMeans Cluster
(h) Feature PCA
(a) Input
(b) Foreground PCA (*ref)
(c) 1st Component of Feature PCA
(d) 2nd Component of Feature PCA
(e) 3rd Compont of Feature PCA
(f) Feature Norm
(g) KMeans Cluster
(h) Feature PCA
DVT denoises the DINOv2 models trained with register tokens. Appending learnable register tokens to the inputs of ViTs is a recently proposed method aimed at removing artifacts in ViTs and enhancing their performance. However, we have found that models trained with registers continue to exhibit certain artifacts, albeit to a lesser extent. Our method is capable of further reducing these artifacts.
*All results are derived from our generalizable denoiser applied to unseen frames during denoiser training.Our proposed per-image denoising approach effectively removes these artifacts through per-image optimization. The 2nd to 4th columns in the visualizations display the original outputs from the DINOv2 ViT-base model, clearly illustrating how positional artifacts negatively affect semantic coherence.

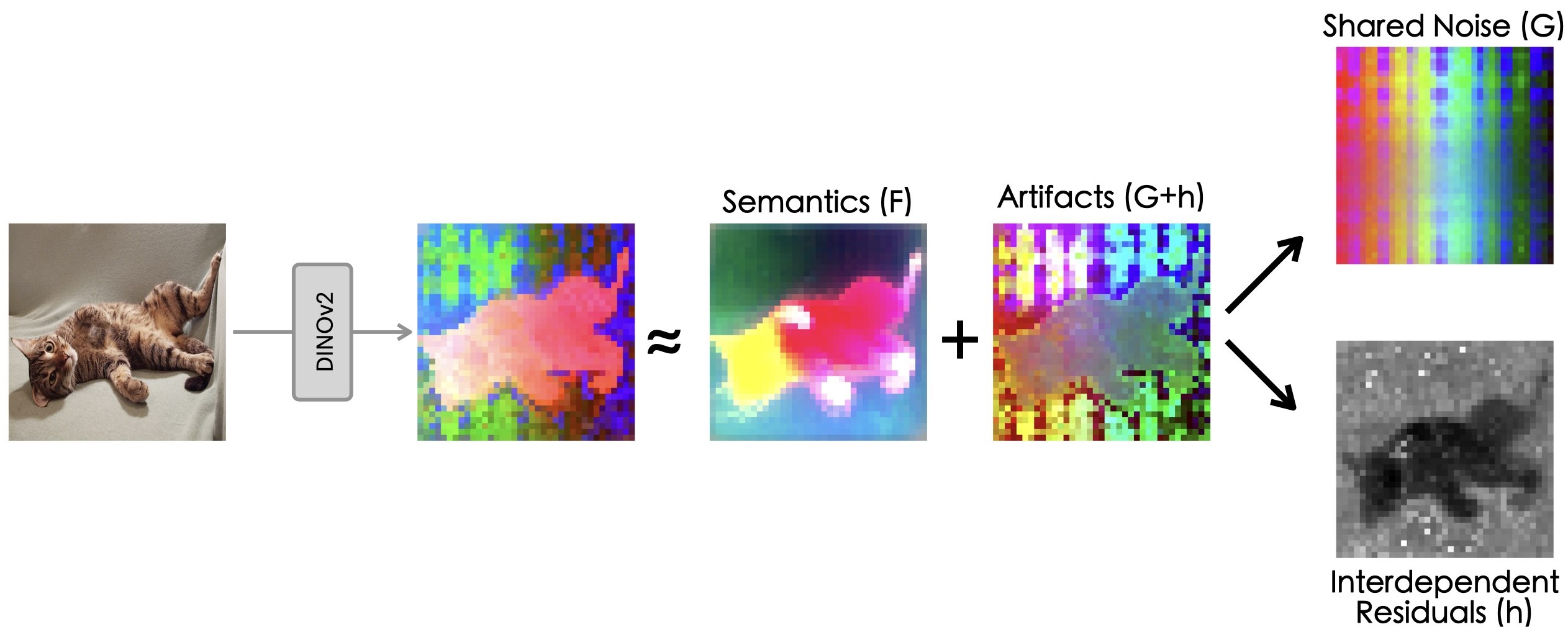
The remaining columns, from the 5th to the last, showcase outputs from our neural field-based denoising approach. At the core of our method is the model:
ViT(x) ≈ F(x) + [G(position) + h(x, position)],
where:
F(x): Represents the denoised semantic features.
G(position): Denotes the shared artifacts across all views.
h(x, position): Models the interdependency between position and semantic content.
After applying per-image denoising to many images, we accumulate a dataset of pairs consisting of noisy ViT outputs y and their denoised counterparts F, denoted as {y, F}, We then train a denoiser network D to predict noise-free features from raw ViT outputs, i.e., F = D(y). The denoiser network is lightweight, consisting of a single Transformer block, and it generalizes well.
Addressing these artifacts can fully unleash the potential of pre-trained ViTs and lead to substantial performance improvements. See Table 1 below.
Table 1: Quantitative performance of DVT. DVT improves differently pre-trained ViTs for dense prediction tasks. We report performance on semantic segmentation (VOC2012, ADE20K), depth prediction (NYUd-v2), and object detection tasks (VOC2007+2012).
| VOC12 Segmentation | ADE20K Segmentation | NYUv2 Depth Estim. | VOC Detec. | ||||
|---|---|---|---|---|---|---|---|
| Method | mIoU (↑) | mAcc (↑) | mIoU (↑) | mAcc (↑) | δ1 (↑) | abs rel (↓) | mAP (↑) |
| (a1) DINO | 63.00 | 76.35 | 31.03 | 40.33 | 73.19 | 0.1701 | 76.4 |
| (a2) DINO + DVT | 66.22 | 78.14 | 32.40 | 42.01 | 73.53 | 0.1731 | 77.1 |
| (b1) DeiT-III | 70.62 | 81.23 | 32.73 | 42.81 | 72.16 | 0.1788 | 75.8 |
| (b2) DeiT-III + DVT | 73.36 | 83.74 | 36.57 | 49.01 | 71.36 | 0.1802 | 77.0 |
| (c1) EVA02 | 71.52 | 82.95 | 37.45 | 49.74 | 63.68 | 0.1989 | 79.4 |
| (c2) EVA02 + DVT | 73.15 | 83.55 | 37.87 | 49.81 | 68.52 | 0.1964 | 80.2 |
| (d1) CLIP | 77.78 | 86.57 | 40.51 | 52.47 | 73.95 | 0.1679 | 80.9 |
| (d2) CLIP + DVT | 79.01 | 87.48 | 41.10 | 53.07 | 74.61 | 0.1667 | 81.7 |
| (e1) DINOv2-reg | 83.64 | 90.67 | 48.22 | 60.52 | 87.88 | 0.1190 | 80.9 |
| (e2) DINOv2-reg + DVT | 84.50 | 91.45 | 49.34 | 61.70 | 88.26 | 0.1157 | 81.4 |
| (f1) DINOv2 | 83.60 | 90.82 | 47.29 | 59.18 | 86.88 | 0.1238 | 81.4 |
| (f2) DINOv2 + DVT | 84.84 | 91.70 | 48.66 | 60.24 | 87.58 | 0.1200 | 81.9 |
@article{yang2024denoising,
author = {Yang, Jiawei and Luo, Katie Z and Li, Jiefeng and Deng, Congyue and Guibas, Leonidas J. and Krishnan, Dilip and Weinberger, Kilian Q and Tian, Yonglong and Wang, Yue},
title = {DVT: Denoising Vision Transformers},
journal = {arXiv preprint arXiv:2401.02957},
year = {2024},
}
We are grateful to many friends, including Jiageng Mao, Junjie Ye, Justin Lovelace, Varsha Kishore, and Christian Belardi, for their fruitful discussions on this work and follow-ups. Katie Luo is supported by an Nvidia Graduate Fellowship. Leonidas Guibas acknowledges the support from a Vannevar Bush Faculty Fellowship. We also acknowledge an unrestricted gift from Google in support of this project.
{kind=link}